Обходим защиту от ботов в Google
Если вы пробовали когда-нибудь написать парсер выдачи Google, то наверняка знаете, что в нем предусмотрен ряд мер, направленных против такого использования поисковой машины. В этой заметке я расскажу о нескольких приемах, позволяющих эти меры обойти.
Дополнение: Чуть более удобный, на мой взгляд, способ парсинга Google описан в посте И еще немного про Google Hack. Тем не менее, эта заметка тоже интересная, так что продолжайте чтение!
Сразу отмечу, что Google Search API не всегда может заменить пользовательский интерфейс Google. Как я отмечал в статье, на которую ведет предыдущая ссылка, как минимум в Search API не поддерживается поиск по блогам. Если же вы просто хотите отслеживать позиции своего сайта, вполне сгодится и Search API.
Чтобы заметка получилась нагляднее, я набросал небольшой скрипт на Perl:
#!/usr/bin/perl
# get-sites.pl script
# Usage: ./get-sites.pl > tmp.txt && cat tmp.txt | sort -u > rslt.txt
# (c) Alexandr Alexeev 2010
# http://eax.me/
use strict;
my $opt = ""; # настройки - кукисы, user-agent и тп
for my $query(1..50) {
for my $page(0..9) {
print STDERR "query = $query, page = $page\n";
my $url = "http://www.google.ru/search?⏎
as_q=$query&as_sitesearch=ru&num=100&start=${page}00&filter=0";
my $cmd = "wget $opt -q '$url' -O -";
# print STDERR "cmd:\n$cmd\n";
NEW_ATTEMPT:
my $data = `$cmd`;
my @sites = $data =~ /http\:\/\/(?:www\.)([0-9a-z-]+\.ru)\//ig;
print STDERR " >> ".(scalar @sites)." sites found\n";
unless(scalar @sites) {
print STDERR " >> sleeping 60 seconds...\n";
sleep 60;
goto NEW_ATTEMPT;
}
print "\L$_\E\n" for(@sites);
sleep 6;
}
}
Задача скрипта – получить список из нескольких тысяч случайных сайтов в зоне RU. В дальнейшем его можно будет использовать для проведения каких-нибудь исследований. Например, можно взять выборку из 10 000 сайтов и определить CMS, которые на них используются.
Так какие же сложности ждут нас при парсинге выдачи гугла? Во-первых, это проверка User-agent. Если ему будет присвоено значение «Wget/...», поисковая система откажется выполнять запрос. Во-вторых – капча. При слишком частом обращении к Google с похожими запросами происходит перенаправление пользователя на sorry.google.com, где ему предлагается ввести цифры с картинки. И в-третьих, при большом количестве запросов с одного IP, система может попросить дать ей отдохнуть пару минут, даже если мы прошли капчу.
Первую проблему решить очень просто – достаточно посмотреть User-agent своего браузера и настроить соответствующим образом утилиту, с помощью которой происходит загрузка страниц (wget, curl, lynx, ...). Я в своих скриптах обычно использую wget, который может замаскироваться под огнелис с помощью ключа –user-agent.
$opt = " --user-agent='Mozilla/5.0 (X11; U; FreeBSD i386; ru-RU; ⏎
rv:1.9.1.10) Gecko/20100625 Firefox/3.5.10'";
С капчей все немного сложнее. Написать свой распознаватель – задача очень непростая, хоть и решаемая. Но к счастью, ломать капчу не придется – достаточно пройти ее один раз. Сначала очищаем кукисы. Для работы с кукисами я использую плагин Cookie Monster Addon:
Затем запускаем наш парсер и ждем, пока Google не начнет ругаться, что наши запросы подозрительно напоминают деятельность компьютерных вирусов.
....
query = 11, page = 0
>> 0 sites found
>> sleeping 60 seconds...
^C
Останавливаем парсер и вводим в Google какой-нибудь запрос. Браузер должен показать что-то вроде этого:
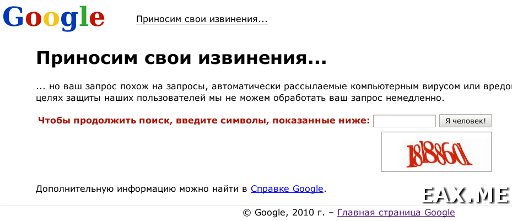
Ничего не заполняя, запускаем tcpdump из под рута:
tcpdump -A -s 1500 dst google.ru and port 80
Ключ -A означает, что перехваченные пакеты нужно выводить в текстовом виде, «-s 1500» – что для каждого пакета должны выводиться только первые 1500 байт (по умолчанию – 68). Если учесть, что в сетях Ethernet это является максимально допустимым размером пакета, мы увидим их целиком. Остальная часть команды и так понятна.
Проходим капчу, останавливаем tcpdump и ищем в перехваченных пакетах кукисы:
....
Host: www.google.ru
User-Agent: Mozilla/5.0 (X11; U; FreeBSD i386; ru-RU; rv:1.9.1.10) ...
Accept: text/html;q=0.9,*/*;q=0.8
Accept-Language: ru-RU,ru;q=0.7,...
Accept-Encoding: gzip,deflate
Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Referer: http://www.google.ru/sorry/...
Cookie: S=sorry=BZXzL3t3l_-lBy59IEcOPQ; ...
Выдираем из HTTP-запроса печеньку (Cookie: ...) и прописываем в нашем скрипте:
$opt .= " --no-cookies --header 'Cookie: S=sorry=BZXzL3t3l_-lBy ...'";
Вот и все – капчи как ни бывало! Удивительно, что Google время от времени не просит пройти ее снова. Может расчет был на время жизни Cookie?
И последняя проблема – это когда Google начинает выдавать страницы вроде той, что приведена на предыдущем скриншоте, только без капчи. У нее есть два решения – либо делать задержки между обращениями к Google (см код скрипта), либо, если время поджимает, работать через список прокси.
Мне кажется, в нашем случае торопиться некуда – можно оставить парсер работать на ночь и на утро получить список из нескольких тысяч сайтов. Кстати, если этот список кому-нибудь нужен – вот он.