Еще немного про Google Hack
Недавно я рассказывал о способе, позволяющем обойти капчу Google, которую поисковик использует в случае получения большого числа похожих запросов с одного IP. За прошедшие две недели я придумал, как еще можно ускорить (и не только ускорить) парсинг выдачи Google, чем и хотел бы сейчас поделиться.
1. Используем прокси
Прием с кукисами и tcpdump действительно позволяет обойти защиту от ботов, однако он имеет несколько существенных недостатков. Во-первых, этот прием неудобный – нужно запускать снифер, проходить капчу, прописывать кукис. Во-вторых, он не надежен – кто знает, как долго тема будет оставаться рабочей? И наконец, способ накладывает ограничение на частоту посылки запросов.
Если бы мы слали запросы через http/socks прокси, ни одной из названных проблем у нас не было. Да, названных проблем мы бы избежали, однако получили бы пару новых. Обычно паблик-прокси медленные и быстро умирают. Потому использовать их мы не будем.
Вместо них я решил использовать анонимайзеры. Кто не в курсе, анонимайзеры – это веб-скрипты, предназначенные для скрытия IP, а также вырезания рекламы из страниц и некоторых других вещей. Пожалуй, самым известным анонимайзером в рунете является Anonymizer.Ru. В сети существуют тысячи анонимайзеров, самый полный список которых можно найти на Proxy.org. Большинство из них работают на скриптах Glype и PHPProxy.
Есть много причин, зачем люди создают сайты-анонимайзеры. Например, можно показывать в начале каждой просматриваемой страницы контекстную рекламу. Или банально собирать пароли от GMail и ВКонтакте. Однако это для нас сейчас не так важно, как то, что анонимайзеры обычно намного быстрее socks-прокси и редко бывают оффлайн. Так от чего бы не слать запросы к Google через них?
Что интересно, искать анонимайзеры мы будем также с помощью Google. Какая ирония. Вот простой запрос, позволяющий собрать список сайтов, на которых работает PHPProxy:
"Rotate13" "Base64" "Strip" inurl:index.php?q=
Строки Rotate13, Base64 и Strip находятся в верхней части страницы, созданной с помощью PHPProxy.
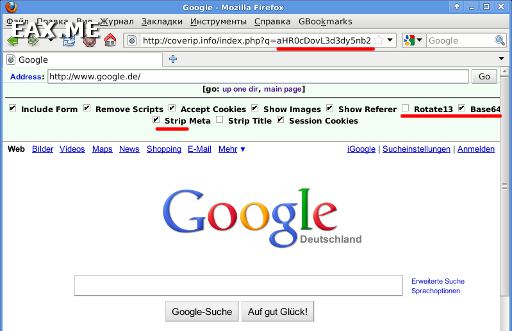
Как видно на скриншоте (знаю, что он мелковат, но видно же!), URL просматриваемой страницы передается PHPProxy в аргументе q закодированный в Base64. Собрав пару десятков таких прокси, мы сможем слать все запросы к Google через них, без необходимости обходить капчу и делать задержки между запросами.
2. Генератор url запросов
Вместо того, чтобы при каждой новой задаче писать новый парсер Google, лучше написать универсальный парсер, принимающий на вход собственно запросы к ПС. А возьмем мы эти запросы откуда? Правильно, получим с помощью генератора запросов. Вот пример такого генератора:
#!/usr/bin/perl
use strict;
my $query = "\"Rotate13\" \"Base64\" \"Strip\" inurl:index.php?q=";
for my $p(0..9) {
for my $zone(qw/.com .net .org .biz .info .de .ru/) {
my $q = "$query site:$zone";
$q =~ s/ /%20/g;
print "http://www.google.ru/search?q=".
"$q&num=100&start=${p}00&filter=0\n";
}
}
Правда, написать такой скрипт проще, чем новый парсер? Кроме того, работая со списком запросов мы можем:
- Перемешать его с помощью команды «cat list.txt | rl > rslt.txt». Посылая запросы вперемешку, мы вызовем у ПС меньше подозрений относительно их естественности;
- Распараллелить парсинг. Просто запускаем несколько процессов-граберов, подав каждому на вход часть списка запросов. И никаких лишних скриптов для этого писать не надо;
- Если грабер будет выводить номера выполненных запросов, мы сможем в любой момент приостановить его. Как только мы снова будем готовы к парсингу (ISP исправил неполадки в сети), удаляем из списка уже обработанные запросы, после чего возобновляем работу.
3. Универсальный грабер
А вот собственно и сам скрипт, посылающий запросы Google:
#!/usr/bin/perl
# Google Parser
# (c) Alexandr Alexeev 2010 | http://eax.me/
use strict;
use MIME::Base64;
my @proxies = split /\n/, `cat proxies.txt`; # список PHPProxy
my $opt = "--timeout=10 --no-check-certificate --user-⏎
agent='Mozilla/5.0 (X11; U; FreeBSD i386; ru-RU; rv:1.9.1.10) ⏎
Gecko/20100625 Firefox/3.5.10'";
my $line = 0;
while(my $url = <>) {
$line++;
chomp $url;
$url .= "&hl=en"; # язык выдачи - только английский
print STDERR "url = $url\n";
NEW_ATTEMPT:
my $proxy_url = $proxies[rand(@proxies)].encode_base64($url);
$proxy_url =~ s/\n//g;
print STDERR "proxy_url = $proxy_url\n";
my $data = `wget $opt -q '$proxy_url' -O -`;
my @sites = $data =~ /<h3 class="r"><a href="[^\?]+index\.php\?q=([^&"]+)"/g;
my @sites = map {
s/(\%3D)/=/g; s/(\%2B)/+/g; s/(\%2F)/\//g;
$_ = decode_base64($_);
s/(&)/&/g;
$_; } @sites;
print STDERR " >> line = $line, ".(scalar @sites)." sites found\n";
if((scalar @sites == 0) && ($data !~ /Your search - <b>[^<]*<\/b> ⏎
- did not match any documents/i)) {
print STDERR " >> ERROR, NEW ATTEMPT...\n";
goto NEW_ATTEMPT;
}
print "$_\n" for(@sites);
}
Я думаю, вы без труда разберетесь в том, как работает этот скрипт (или нет, тогда читаем мои уроки по Perl). Ключевая его часть – это поиск ссылок в ответе Google. Притом ссылки эти преобразованы используемыми нами анонимайзерами, список которых подгружается из файла proxies.txt. Потому прежде, чем выводить список ссылок пользователю, нужно их декодировать из Base64.
4. Валидатор прокси
Вот нашли мы пару рабочих анонимайзеров (пункт 1), сохранили в proxies.txt. Затем сгенерировали список запросов (2) и обработали его с помощью парсера (3). Что теперь делать с полученным списком ссылок?
Для начала нужно отфильтровать ссылки вида [сайт]/index.php?q=, поскольку именно так начинается url страниц, просматриваемых через PHPProxy, после чего удалить повторяющиеся строки:
cat google-proxies-serp.txt | \
grep -Eio '(https?://[^&]+/index\.php\?q=)' | \
sort -u > check-proxies.txt
Эта была, так сказать, предварительная обработка. После нее найденные прокси нужно проверить на работоспособность:
#!/usr/bin/perl
use strict;
my @proxies = split /\n/, `cat check-proxies.txt`;
for my $p(@proxies) {
my $data = `wget --timeout=10 --user-agent='Mozilla/5.0 (X11; U; ⏎
FreeBSD i386; ru-RU; rv:1.9.1.10) Gecko/20100625 Firefox/3.5.10' ⏎
-q '${p}aHR0cDovL2dvb2dsZS5jb20v' -O -`;
if($data =~ /<title>Google<\/title>/) {
print "$p\n";
} else {
print STDERR "ERROR: $p\n";
}
}
Алгоритм простой – пытаемся зайти на google.com (в base64 – aHR0cDovL2dvb2dsZS5jb20v), и если в ответе скрипта будет title, как на Google, значит анонимайзер рабочий.
В результате описанных в пунктах 1-4 действий, мне удалось получить список из 106 рабочих анонимайзеров. По-моему, этого более, чем достаточно для парсинга выдачи Google. К тому же, теперь у меня есть универсальный парсер, который уже несколько раз успел мне пригодиться. Надеюсь, и вы найдете ему применение!