Пишем простой интерпретатор на Haskell
Сегодня совместными усилиями мы с вами создадим простенький скриптовый язык программирования. В нем не будет массивов или условных операторов, зато будут целочисленные переменные и множество операций над ними. Писать, как вы уже поняли, будем на замечательном языке Haskell. Также мы познакомимся с «компиляторами компиляторов» Alex и Happy.
Вспоминаем теоретическую часть
Каким образом исходный код программы преобразуется в исполняемый файл? Это происходит в несколько шагов/этапов. Выходные данные, полученные на шаге N, служат входными данными для шага N+1. На вход такому «конвейеру» байт за байтом подается исходный код, а на выходе получается программа. Что же это за этапы?
Первый этап – это лексический анализ. На этом шаге код программы, скажем:
foo = foo + 1;
разбивается на лексемы (строки «foo», «=», «+», ...), их которых затем получается последовательность токенов:
[ ИДЕНТ "foo", РАВНО, ИДЕНТ "foo", ПЛЮС, 1, ТОЧКА_С_ЗАПЯТОЙ ]
То есть, лексический анализатор разбивает программу на элементарные составные части – операторы, ключевые слова, имена переменных и т.п. Также на этапе лексического анализа опционально удаляются комментарии, а запись 0b1101 преобразуется в число 13.
Выход лексического анализатора подается на вход синтаксическому анализатору (или парсеру), задача которого заключается в проверке синтаксиса (такой штуки, которая не позволяет писать десять знаков равенства подряд) и преобразовании последовательности токенов в дерево синтаксического разбора. На этом этапе мы уже не беспокоимся о том, что в коде программы есть табуляции или переносы строк. Также мы точно знаем, что программа не содержит лексическую ошибку, то есть в ней нет несуществующих операторов или переменной, имя которой начинается с цифры.
Дерево разбора представляет собой структуру наподобие следующих:
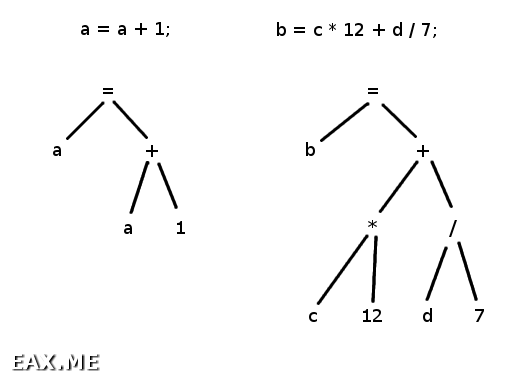
Рассмотрим левое дерево. Читая его снизу вверх, получим «взять значение переменной a и число 1, сложить их, а затем присвоить результат переменной a», что в точности описывает поведение программы. Правое дерево наглядно демонстрирует, что при его построении были учтены приоритеты операторов, то есть сначала производятся умножение и деление и только потом сложение.
Также вы можете заметить, что ни одно из деревьев не содержит токена «точка с запятой». Вообще-то, узлы дерева могут содержать не токены, а какие-то другие типы данных. Или токены, но не те, что пришли от лексического анализатора. Скажем, инкремент (оператор ++) может быть преобразован в дерево, представленное слева.
Происходящее за лексическим и синтаксическим анализом зависит от решаемой задачи, реализации компилятора, пестрости рубашек его автора и т.п. За ними может следовать (или не следовать) семантический анализ, цель которого состоит в обнаружении обращений к несуществующим переменным, вызовов функций с неверным числом аргументов и т.п. Если мы пишем оптимизирующий компилятор, то за семантическим анализом последует оптимизация кода, затем – непосредственно генерация кода и, возможно, его оптимизация на уровне машинных команд.
Наш интерпретатор не будет генерировать никакого кода, работая напрямую с синтаксическим деревом. Семантика будет проверяться прямо во время интерпретации. Оптимизация производиться не будет.
Поскольку редкий компилятор (интерпретатор, транслятор, ...) обходится без лексического и синтаксического анализатора, была написана масса генераторов этих самых анализаторов. «Компиляторы компиляторов» экономят время и силы, а также существенно сокращают количество багов в создаваемых с их помощью компиляторах. Мы воспользуемся генераторами Alex и Happy. Устанавливаются они, как и следовало ожидать, с помощью утилиты cabal.
Лексический анализатор
Все исходники к этой заметке вы найдете в этом архиве.
Код лексического анализатора находится в файле Lex.x. Он слишком объемен, чтобы приводить его здесь целиком, но при этом не содержит какой-то особой магии. Мы просто определяем тип данных «токен»:
data Token = TInt Int | TIdent String
| TPlus | TMinus | TMul | TDiv | TMod
| ...
instance Show Token where
show x = case x of
TInt i -> show i
TIdent s -> s
TModifSet -> "="
TPlus -> "+"
TMinus -> "-"
TMul -> "*"
TDiv -> "/"
TMod -> "%"
...
... и задаем старые добрые регулярные выражения, определяющие, какой лексеме (последовательности символов) какой токен соответствует:
$alpha = [a-zA-Z]
$digit = [0-9]
$hex = [0-9a-fA-F]
$bin = [0-1]
tokens :-
$white+ ;
$digit+ { \(p,_,_,s) len -> return $ TInt (read $ take len s) }
"+" { \(p,_,_,s) len -> return $ TPlus }
"-" { \(p,_,_,s) len -> return $ TMinus }
"*" { \(p,_,_,s) len -> return $ TMul }
"/" { \(p,_,_,s) len -> return $ TDiv }
"%" { \(p,_,_,s) len -> return $ TMod }
...
На самом деле, это не сам код лексического анализатора, а что-то вроде его заготовки. А вот если выполнить команду:
alex Lex.x
... то будет сгенерирован файл Lex.hs, содержащий непосредственно код. Убедиться, что он действительно работает, можно с помощью следующей программы:
module Main where
import Lex
main = do
s <- getContents
putStrLn $ case alexScanTokens s of
Right lst -> concatMap (\t -> "'" ++ show t ++ "' ") lst
Left err -> "ERROR: " ++ err
Проверяем:
$ alex Lex.x
$ ghc LexMain.hs
[1 of 2] Compiling Lex ( Lex.hs, Lex.o )
[2 of 2] Compiling Main ( LexMain.hs, LexMain.o )
Linking LexMain ...
$ echo 'a = a + 1; a--;' | ./LexMain
'a' '=' 'a' '+' '1' ';' 'a' '--' ';' '(EOF)'
Согласитесь, ничего сложного.
Синтаксический анализатор
Синтаксис языка программирования обычно задается с помощью контекстно-свободной грамматики, для описания которой в свою очередь используется BNF. Откроем файл Synt.y и найдем в нем описание грамматики нашего языка программирования:
Program:
ExprList { Program $1 }
ExprList:
Expr ';' ExprList { ExprList $1 $3 }
| 'EOF' { ExprEnd }
Expr:
ident '=' RVal { Expr $1 $3 }
...
RVal:
RVal '+' RVal { BinOp Add $1 $3 }
| RVal '-' RVal { BinOp Sub $1 $3 }
| RVal '*' RVal { BinOp Mul $1 $3 }
| RVal '/' RVal { BinOp Div $1 $3 }
...
| RVal '?' RVal ':' RVal { IfElse $1 $3 $5 }
| '(' RVal ')' { $2 }
| int { IntVal $1 }
| ident { IdentVal $1 }
Символы в кавычках, а также int и ident – это просто другие обозначения токенов:
%token
int { TInt $$ }
ident { TIdent $$ }
'+' { TPlus }
'-' { TMinus }
'*' { TMul }
'/' { TDiv }
'%' { TMod }
...
Также Synt.y содержит описание типа «синтаксическое дерево»:
data Program = Program ExprList
deriving (Show, Eq)
data ExprList = ExprList Expr ExprList | ExprEnd
deriving (Show, Eq)
data Expr = Expr String RVal
deriving (Show, Eq)
data BinOpType = Add | Sub | Mul | Div | Mod | LogOr | LogXor
| LogAnd | BinAnd | BinOr | BinXor
| Eq | Lt | Le | Shl | Rol
deriving (Show, Eq)
data UnOpType = LogNot | BinNot | Neg
deriving (Show, Eq)
data RVal = IntVal Int | IdentVal String
| BinOp BinOpType RVal RVal | UnOp UnOpType RVal
| IfElse RVal RVal RVal
deriving (Show, Eq)
Некоторые грамматики, включая нашу, содержат неоднозначности. Это приводит к конфликтам – ситуациям, когда по заданной грамматике и заданной последовательности токенов можно построить несколько различных деревьев синтаксического разбора. Если грамматика содержит конфликты, Happy сообщит об их наличии при генерации кода синтаксического анализатора. Есть два типа конфликтов.
Наличие reduce/reduce конфликтов означает, что некой последовательности токенов может соответствовать более одного нетерминального символа. Другими словами, при некоторых условиях может оказаться неясно, то ли в программе объявляется функция, то ли происходит деление на десять. Избавиться от reduce/reduce конфликтов можно только изменив грамматику. Наша грамматика таких конфликтов не содержит.
Конфликты типа shift/reduce возникают, когда некая последовательность токенов может быть представлена только одним нетерминалом, но, тем не менее, несколькими деревьями разбора. Например, 1 + 2 * 3 – это (1 + 2) * 3 или 1 + (2 * 3)? Очевидно, наша грамматика в изобилии содержит такого рода конфликты. Разрешаются они с помощью приоритетов и ассоциативности операторов:
%right '=' '+=' '-=' '*=' '/=' '%=' ...
%right '?' ':'
%left '||'
%left '^^'
%left '&&'
%left '|'
%left '^'
%left '&'
%left '==' '<>'
%left '<' '<=' '>' '>='
%left '>>' '<<' '<<<' '>>>'
%left '+' '-'
%left '*' '/' '%'
%right '!' '~'
%right NEG
%%
Чем ниже оператор в этом списке, тем выше его приоритет. Чтобы не накосячить, я подсмотрел приоритеты и ассоциативность у Кернигана и Ритчи. Что такое NEG, будет показано немного ниже.
Теперь о shift/reduce конфликтах можно не волноваться – если операторы имеют разный приоритет, дерево синтаксического разбора будет строиться в соответствии с их приоритетами, а если одинаковый, в ход вступит ассоциативность. Например, оператор сложения является левоассоциативным, потому выражение 1 + 2 + 3 + 4 – это на самом деле ((1 + 2) + 3) + 4.
Оператор может быть безассоциативным (%nonassoc). Если два таких оператора находятся в непосредственной близости, это означает синтаксическую ошибку. Также оператор может менять свой приоритет в зависимости от контекста. Классический пример – унарный минус:
RVal:
RVal '+' RVal { BinOp Add $1 $3 }
| RVal '-' RVal { BinOp Sub $1 $3 }
| RVal '*' RVal { BinOp Mul $1 $3 }
| RVal '/' RVal { BinOp Div $1 $3 }
...
| '-' RVal %prec NEG { UnOp Neg $2 }
...
Все, с матчастью покончено! Теперь попробуем синтаксический анализатор в действии:
$ happy Synt.y
$ ghc SyntMain.hs
[2 of 3] Compiling Synt ( Synt.hs, Synt.o )
[3 of 3] Compiling Main ( SyntMain.hs, SyntMain.o )
Linking SyntMain ...
$ echo 'a = 0xFF; b = a << 3; b |= 0b10;' | ./SyntMain
Program (ExprList (Expr "a" (IntVal 255)) (ExprList (Expr "b"
(BinOp Shl (IdentVal "a") (IntVal 3))) (ExprList (Expr "b"
(BinOp BinOr (IdentVal "b") (IntVal 2))) ExprEnd)))
Обратите внимание на то, какое синтаксическое дерево было построено для последнего выражения. Наш синтаксический анализатор производит очень много подобный преобразований.
Интерпретатор (наконец-то!)
Исходный код интерпретатора вы найдете в файле Interpret.hs. Этот код прост и очевиден, так что оставляю его вам для самостоятельного изучения. А вот как это работает:
$ ghc InterpretMain.hs
[3 of 4] Compiling Interpret ( Interpret.hs, Interpret.o )
[4 of 4] Compiling Main ( InterpretMain.hs, InterpretMain.o )
Linking InterpretMain ...
$ ./InterpretMain
a = 1 * 2 + 3 * 4;
a = 14
b = 1 * (2 + 3) * 4;
a = 14
b = 20
c = a > b ? a / b : b / a;
a = 14
b = 20
c = 1
d = 1 $ 2;
lexical error
d + + + +
syntax error
e = a + b + c + d;
undefined variable 'd'
a %= 0;
divide by zero
Ну разве это не прекрасно? Теперь мы можем пачками штамповать компиляторы, трансляторы и интерпретаторы, а также парсеры различных форматов, статические анализаторы кода типа lint и perlcritic, обфускаторы и деобфускаторы, программы для подсветки синтаксиса и т.п. Как я уже когда-то писал, это целый новый мир!
Заключение
В качестве источника дополнительной информации настоятельно рекомендую драконью книгу. Сей труд – библия разработчика компиляторов. Вы просто обязаны прочитать его от и до, если серьезно намерены создать свой Единственный Правильный Язык Программирования.
Ваше домашнее задание, если вы примите его, заключается в доработке интерпретатора таким образом, чтобы он поддерживал строки, массивы, хеши, условные операторы, циклы и функции. Для выполнения миссии вы можете выбрать любых напарников. В случае успеха, вы должны послать мне пулл реквест с соответствующими изменениями. Вы нужны нам, мистер Хант.