Идея организации данных для in-memory СУБД
Арендовать сервер с 1+ ТБ оперативной памяти вот уже много лет не является проблемой. Например, на сегодняшний день стоимость инстанса x2gd.16xlarge в AWS составляет ~4000$/мес, и это лишь первое попавшееся мне предложение. Многие бизнесы помещаются в память одного-единственного сервера. Отсюда возникает интерес к in-memory СУБД. Ведь при прочих равных они обеспечивают большую производительность, чем условный PostgreSQL. Давайте подумаем, как могла бы выглядеть организация данных в in-memory СУБД, если бы мы писали ее с нуля.
Когда я пытаюсь представить себе одну таблицу в in-memory СУБД, мое сознание почему-то рисует следующее:
По-видимому, тут имелось в виду какое-то дерево поиска. В реальности следует использовать B- или B+деревья. Число связей между узлами было сокращено для упрощения картинки. Получается, таблицы будут index organized. Зачастую это удобно. Любой кортеж можно адресовать по id таблицы и первичному ключу. Раз речь пошла о кортежах, то СУБД будет условно считаться за реляционную.
Первое, что меня интересует – как реализовать транзакции? Желательно, чтобы решение было как можно более простым. Во-первых, так меньше вероятность допустить ошибку. Во-вторых, in-memory СУБД помимо прочего привлекательны своей простотой (относительной, естественно). Одним из самых простых является решение из мира распределенных систем:
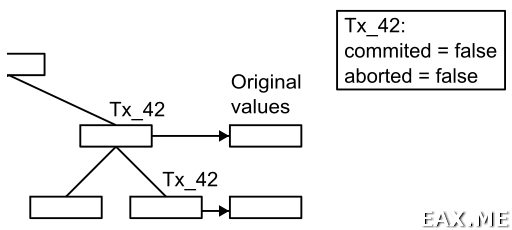
Более детально сей алгоритм я описывал в посте Шардинг, перебалансировка и распределенные транзакции в реляционных базах данных. Алгоритм я называю «транзакциями Рысцова», потому что Денис Рысцов его популяризировал. Кто же изобрел алгоритм, мне неизвестно. Он описан во многих источниках.
В двух словах напомню, в чем тут идея. При изменении кортежа на самом деле он не изменяется. Вместо этого мы записываем новое значение кортежа, которое также содержит ссылку на объект «транзакция». Состояние этого объекта может быть изменено на committed или aborted, притом, происходит это атомарно. Все читатели и писатели осведомлены о существовании транзакций. Поэтому, увидев в таблице грязные данные, они проверяют состояние транзакции. Если она еще исполняется, значит, эти данные видны только внутри создавшей их транзакции. Если транзакция откатилась, значит мы видим мусорные данные, которые можно безопасно подчистить. Иначе существует вероятность, что данные нам видны, с точностью до уровня изоляции и соответствующих ему проверок видимости.
Здесь мы исходим из предположения, что транзакции завершаются успешно чаще, чем отменяются. По этой причине мы сразу помещаем новое значение кортежа в дерево поиска и ссылаемся на прежнее значение. В пессиместичной системе выгоднее делать наоборот.
Стоит отметить, что наш подход не позволяет двум транзакциям модифицировать одни и те же кортежи. Возможный вариант разрешения конфликтов на запись состоит в том, чтобы вторая пишущая транзакция блокировалась до завершения первой пишущей транзакции. Так как мы имеем дело с in-memory СУБД, то время жизни транзакций должно быть невелико. Следует однако помнить об опасности встать в deadlock.
Был получен уровень изоляции read committed. Если применить смекалочку и кэшировать ранее видимые данные, то получится repeatable read. Можно пойти дальше и ввести что-то вроде UNDO лога со старыми значениями кортежей.
Тем более, что частично такой лог у нас уже есть:
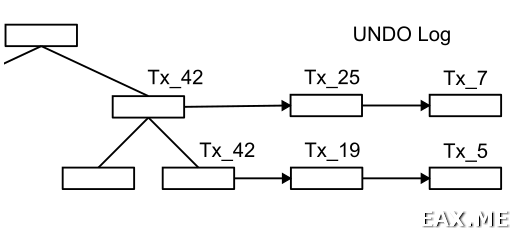
Без UNDO лога'а не видать нам snapshot isolation, как своих ушей. Ведь всегда остается вероятность, что пока мы исполняем SELECT * FROM my_table, другие транзакции модифицирует кортежи в таблице, а значит данные мы прочитаем неконсистентные. Наличие UNDO лога гарантирует, что нужные нам данные не исчезнут бесследно. Точнее говоря, исчезнут не сразу.
Естественным образом встает вопрос об очистке UNDO лога от записей, которые точно не может видеть ни одна транзакция. Особенно если мы задумали держать UNDO лог в памяти, как и все остальные данные. В меру удачным решением будет хранение лога в кольцевом буфере фиксированного размера. Транзакции, которые выполняются слишком долго и пытаются заглянуть слишком далеко в прошлое, придется завершать с ошибкой. Это нередкий компромисс, на который приходится пойти в системах с UNDO логом. Следует принять во внимание, что UNDO лог может быть бутылочным горлышком. К нему обращаются как пишущие, так и читающие транзакции.
Если нужно поддерживать тяжелые UPDATE / DELETE запросы в одну транзакцию, то имеет смысл посмотреть в сторону расширения UNDO лога при помощи mmap. Есть также вариант реализовать «mmap вручную». А еще есть вариант ничего не делать, и положиться на swapping со стороны ОС. Можно придумать и более хитрые подходы. Но, по-видимому, они приведут к чрезмерному усложнению системы, чего хотелось бы избежать.
Просто наличие UNDO лога'а еще не дает нам snapshot isolation. Суть проблемы иллюстрирует следующая картинка:
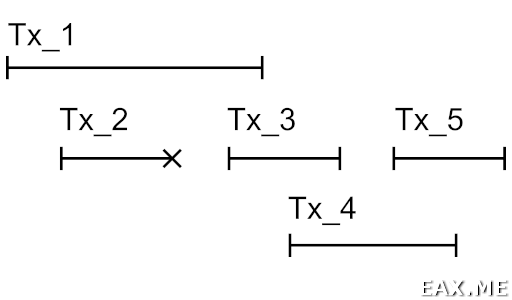
Здесь изображена временная диаграмма выполнения транзакций. Возьмем для примера Tx_4. Эта транзакция видит изменения, внесенные Tx_1, так как Tx_1 завершилась успешно и сделала это до запуска Tx_4. Изменения Tx_2 не видны никому, так как транзакция откатилась. Изменения Tx_3 не видны в Tx_4, так как Tx_3 еще не завершилась на момент начала Tx_4. Изменения Tx_5 также не видны из транзакции Tx_4, так как Tx_5 запустилась позднее.
Случай с Tx_2 на самом деле нам не интересен и показан лишь для полноты картины. Как было описано выше, все изменения Tx_2 будут отброшены, как мусорные. Все, что нужно Tx_4 для проверки видимости – это знать список транзакций, исполнявшихся на момент запуска Tx_4.
Правила проверки видимости получаются такими:
- Если встретили мертвые / мусорные данные, то их не видит никто. Эти изменения неплохо бы откатить;
- Если встретили изменения, внесенные транзакцией, чей id больше id текущей транзакции, то это изменения из будущего. Мы их не видим;
- Если встретили изменения, внесенные транзакцией, чей id меньше id текущей транзакции, то они видны, если id другой транзакции нет в списке исполнявшихся на момент запуска нашей транзакции;
Особого внимания заслуживает видимость изменений, внесенных самой же транзакцией. На первый взгляд, собственные изменения должны быть видны всегда. Но это не так. Рассмотрим случай с запросом UPDATE foo WHERE bar. Он может создавать новые версии кортежей, удовлетворяющих условию. Чтобы запрос не зациклился, он не должен видеть внесенные им же изменения в ходе итерации по кортежам. Описанный сценарий известен, как Halloween problem. Для борьбы с ним в PostgreSQL кортежи хранят t_cid – номер команды внутри транзакции, изменившей кортеж.
Для in-memory СУБД можно придумать и другие решения. Например, можно делать два прохода. На первом проходе проставляется флаг «этот кортеж предстоит изменить». На втором кортеж изменяется, а флаг сбрасывается. Если встретили кортеж без флага, то он игнорируется.
Коль скоро речь зашла об id транзакций, то в его качестве я бы выбрал uint64 и просто инкрементировал счетчик для каждой новой транзакции. Даже если СУБД каким-то чудом выдаст 1 млрд TPS, то id транзакций закончатся через 584 года. Принимая во внимание, что id транзакций живут исключительно в памяти, и что их счетчик сбрасывается при перезапуске СУБД, пару-тройку бит из uint64 можно использовать под какие-то другие нужды.
К слову о других нуждах, при удалении кортежа на его место следует писать так называемый tombstone. Последний может быть удален из дерева поиска, если он не ссылается ни на какие данные из UNDO лога. Например, когда все старые версии кортежа были удалены в результате ротации кольцевого буфера. Одного бита от uint64 как раз достаточно для хранения признака tombstone. Еще один бит можно использовать для решения Halloween problem.
Так вот, теперь у нас есть snapshot isolation. Нужен он нам не от хорошей жизни, а чтобы писать checkpoint'ы на жесткий диск. Писать достаточно первичный ключ и полезную нагрузку кортежа. Ссылки на UNDO лог и id транзакций нужны только в памяти, во время работы СУБД. Структуру дерева поиска сохранять тоже нет смысла. Дерево проще перестроить с нуля при следующем запуске. Вся запись происходит последовательно. Данные можно еще и сжимать каким-нибудь LZ4.
Заметьте, что процесс снятия checkpoint'а является особым в том смысле, что он препятствует ротации UNDO лога. То есть, не должно возникнуть такой ситуации, что нужные checkpoint'у данные попали в UNDO лог, после чего были удалены. В граничном случае checkpoint может блокировать работу пишущих транзакций.
Скорость записи у современных NVMe SSD дисков составляет 3000-5000 МБ/с. Таким образом, запись 1 ТБ данных должна занимать от 3 до 6 минут. В ряде задач потеря данных за пару десятков минут в случае аварийной остановки системы не является критичной, лишь бы данные были консистентны. Если же такие потери недопустимы, то помимо checkpoint'ов нужно писать логический REDO лог. Он должен содержать информацию обо всех изменениях с момента завершения предыдущего checkpoint'а и до завершения следующего checkpoint'а, включая ROLLBACK'и. Когда есть REDO лог, то напрашивается и репликация.
Субъективно, главная проблема описанного решения состоит в том, что скорость чтения с NVMe SSD не намного превышает скорость записи. Значит, при большом объеме данных время запуска СУБД может измеряться минутами. Это время может быть и больше, особенно при наличии вторичных индексов. Последние будет быстрее перестроить, чем читать с диска, однако это все еще не бесплатно.
Думается, что в силу названных обстоятельств Picodata использует Raft. Наличие реплик и leader election позволяет устанавливать обновления СУБД без остановки использующих ее приложений. Характерно, что выбор лидера можно реализовать и без Raft.