Очереди заданий и пулы процессов в Erlang
Многие программы на Erlang прекрасно распараллеливаются. Если некая задача разбивается на независимые части, мы можем просто создать для каждой части отдельный процесс. Однако процессы в Erlang хоть и дешевые, но не бесплатные. Бездумно наплодив кучу процессов, можно с легкостью уронить все приложение. Давайте попробуем решить эту проблему, создав пул процессов фиксированного размера. Задания будут раздаваться этим процессам при помощи gen_server'а, хранящего очередь задач.
Соответствующую библиотеку и автоматические тесты к ней вы найдете на GitHub. Не удивлюсь, если выяснится, что такую библиотеку уже кто-то когда-то писал. Однако мне как-то пофиг, потому что при ее написании я ощутил прилив ценного экспириенса. О деталях реализации будет рассказано в будущих постах. В этой же заметке все внимание будет уделено интерфейсу библиотеки и конкретному профиту от ее использования.
В качестве примера рассмотрим задачу взлома MD5-хэша методом грубой силы. Нам понадобится модуль, реализующий поведение task_queue:
-module(bruteforce_worker).
-behaviour(task_queue).
-export([
init/1,
process_task/2,
terminate/2,
code_change/3
]).
-record(state, {}).
init(_Args) ->
#state{}.
process_task({md5_bruteforce, Postfix, Alph, Hash, Receiver}, State) ->
[ begin
Password = [Prefix1, Prefix2, Prefix3 | Postfix],
case crypto:md5(Password) =:= Hash of
true ->
Receiver ! { password_found, Password };
false ->
ok
end
end || Prefix1 <- Alph, Prefix2 <- Alph, Prefix3 <- Alph ],
{ok, State}.
terminate(_Reason, _State) ->
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
В поведениях (behaviors) на самом деле нет ничего магического. Соответствующий модуль, в данном случае – task_queue, должен экспортировать функцию behaviour_info/1, которая определяет, какие функции должен экспортировать модуль, реализующий поведение:
-module(task_queue).
-export([
behaviour_info/1,
% ... skipped ...
]).
behaviour_info(callbacks) ->
[
{init, 1},
{process_task, 2},
{terminate, 2},
{code_change, 3}
];
behaviour_info(_Other) ->
undefined.
Как видите, модуль bruteforce_worker действительно экспортирует указанные функции. Совсем не сложно, правда?
Главной функцией воркера является process_task/2. Она принимает на вход очередную задачу, которая в данном случае описывается кортежем, но вообще может быть чем угодно, а также текущее состояние воркера. Функция неким образом обрабатывает задачу, после чего возвращает новое состояние воркера. После выполнения задачи воркер идет в очередь за новой задачей, после чего управление вновь передается в process_task/2. Если задач нет, воркер ничего не делает до их появления.
Создание новой очереди задач и заданного количества воркеров производится следующим образом:
{ok, TaskQueue} =
task_queue:start_link(
bruteforce_worker, [],
[{workers_num, 10},{unique_tasks, false}]).
Первым аргументом задается имя модуля, в котором реализовано поведение воркера, вторым – аргументы, передаваемые функции init/1, третьим – настройки очереди задач. Помимо функции start_link/3 предусмотрена функция start_link/2, которая использует настройки по умолчанию. Также есть функции start/2 и start/3, которые отличаются от start_link/N тем, что не линкуют к текущему процессу супервизор, который следит за воркерами и менеджером задач.
Доступные опции и значения по умолчанию:
{workers_num, 10}, количество воркеров;{unique_tasks, false}, не добавлять задачу в очередь, если точно такая же задача уже есть в очереди;{workers_max_r, 0}и{workers_max_t, 1}, если за workers_max_t секунд произойдет более workers_max_r перезапусков воркеров, прибить все процессы, созданныеstart/Nилиstart_link/N;
После создания очереди задач, мы можем помещать в нее задачи следующим образом:
task_queue:in(
{md5_bruteforce, "aa", lists:seq($a,$z), Hash, self()},
TaskQueue).
Для добавления задачи в самое начало очереди предусмотрена функция in_r/2. В любой момент мы можем определить текущую длину очереди, а также, является ли она пустой, с помощью функций len/1 и is_empty/1 соответственно. Вспомнить значение флага unique_tasks, переданного при создании очереди, поможет функция unique_tasks/1. Все названные функции выполняются за O(1) независимо от текущей длины очереди.
Чтобы прибить воркеров и менеджера задач, скажите stop/1. Будьте осторожны с этой функцией, если для создания очереди и воркеров была использована start_link/N.
С интерфейсом разобрались, теперь переходим к профиту. Давайте выясним, насколько в действительности можно ускорить взлом MD5-хэшей при помощи распараллеливания задачи. Я использовал примерно такой бенчмарк:
timer:tc(fun() ->
{ok, TaskQueue} = task_queue:start(
bruteforce_worker, [], [{workers_num, 8}]),
Hash = crypto:md5("zzzzzz"),
Alph = lists:seq($a, $z),
Parent = self(),
spawn(fun() ->
[task_queue:in({md5_bruteforce, [A,B,C], Alph, Hash, Parent},
TaskQueue) || A <- Alph, B <- Alph, C <- Alph]
end),
Rslt = receive X -> X end,
task_queue:stop(TaskQueue),
Rslt
end).
Параметр workers_num менялся в диапазоне от 1 до 8. Для каждого значения параметра проводилось три теста, после чего бралось среднее значение времени. Использовалась машина, оснащенная процессором Intel Core i7-3770K частотой 3.5 GHz с 4-мя физическими ядрами.
В результате у меня получилась такая картинка:
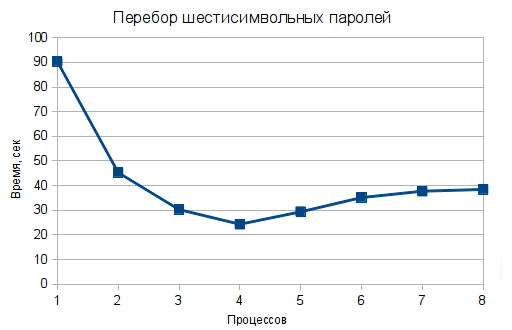
Смотрите, как здорово. Мы без особых усилий можем ускорить нашу программу почти в четыре раза! При этом в htop, само собой разумеется, мы видим 100%-ую загрузку ровно того же количества ядер, сколько воркеров было запущено.
Следует обратить внимание на важность выбора правильного размера одной задачи. Если создавать по задаче на один пароль или на 26 паролей, картинка будет совсем не такой красивой.
Среди имеющихся у меня идей по улучшению библиотеки хочется отметить:
- Добавление поддержки priority queue (например);
- Возможность запуска воркеров на других нодах с указанием, на какой ноде сколько воркеров запустить;
- В настоящее время воркеры «тянут» задачи из очереди, но также можно попробовать «толкать» задачи воркерам случайным образом, round robin'ом или путем нахождения воркера, которому в настоящее время поручено меньше всего задач;
- В последнем случае также можно перераспределять задачи по мере освобождения воркеров;
- Сейчас в случае, если задача убивает воркера, задача теряется – можно добавить указание максимального числа попыток на выполнение задачи, в том числе infinite;
- Было бы неплохо реализовать в библиотеке регистрацию менеджера очереди под локальным или глобальным именем;
- Кажется, было бы удобно создавать воркеров не только из модулей, но и из лямбда-функий арности два, реализующих process_task;
Уверен, у вас тоже есть идеи. Не стесняйтесь делиться ими в комментариях!
Дополнение: Пример использования Common Test, EUnit и Meck