CouchDB 2.0: краткий обзор и мои первые впечатления
CouchDB (не путать с Couchbase!) – документо-ориентированная СУБД, написанная на языке Erlang. В вышедшей недавно версии 2.0 в CouchDB добавили Riak-подобное шардирование, что наконец-то делает эту СУБД кому-то интересной. К тому же, в отличие от Riak, в CouchDB всегда была совершенно бесплатная (не в enterprise edition версии и т.д.) кросс-датацентровая master-slave и master-master репликация. Давайте попробуем разобраться, как же этим хозяйством вообще пользоваться, и подходит ли оно уже для продакшена.
Установка
Для своих страшных экспериментов я использовал Ubuntu 16.04. Готовых пакетов для различных дистрибутивов Linux разработчики CouchDB не предоставляют, поэтому имеет смысл один раз настроить его в Docker или LXC-контейнере, и потом использовать этот контейнер на всех узлах кластера. Для быстрой установки CouchDB мной был написан bash-скрипт. Имеет смысл сразу воспользоваться им. В ближайших двух параграфах я расскажу, как этот скрипт работает.
Ставим зависимости:
sudo apt-get update
sudo apt-get --no-install-recommends -y install \
build-essential pkg-config runit erlang \
libicu-dev libmozjs185-dev libcurl4-openssl-dev
Качаем архив с исходниками с зеркала, которое предложат на официальном сайте. Затем говрим:
tar -xvzf apache-couchdb-2.0.0.tar.gz
cd apache-couchdb-2.0.0/
./configure && make release
Создаем пользователя couchdb:
sudo adduser --system \
--no-create-home \
--shell /bin/bash \
--group --gecos \
"CouchDB Administrator" couchdb
Копируем rel/couchdb в домашний каталог пользователя и выставляем правильные права:
sudo cp -R rel/couchdb /home/couchdb
sudo chown -R couchdb:couchdb /home/couchdb
sudo find /home/couchdb -type d -exec chmod 0770 {} \;
sudo sh -c 'chmod 0644 /home/couchdb/etc/*'
Проверяем, что все было сделано правильно:
sudo -i -u couchdb /home/couchdb/bin/couchdb
У меня в логи стали сыпаться ворнинги про отсутствующую базу данных _users. Не переживайте, это мы скоро исправим.
На http://localhost:5984 должны увидеть:
{
"couchdb": "Welcome",
"version": "2.0.0",
"vendor": {
"name": "The Apache Software Foundation"
}
}
Заметьте, что все общение клиентов с CouchDB происходит по REST API (иногда не REST, а просто какому-то кастомному HTTP API), со всеми вытекающими отсюда преимуществами и недостатками.
На http://localhost:5984/_utils/ увидим красивый веб-интерфейс вроде такого:
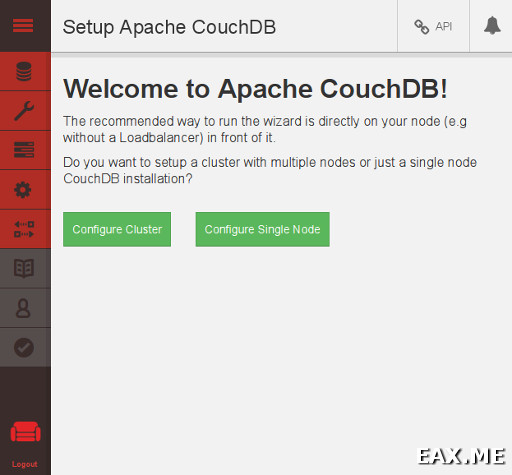
В веб-интерфейсе открываем Setup и создаем кластер из одной ноды (там все просто). После этого в логи перестанут сыпаться какие-либо ошибки.
Автозапуск через runit
Для автоматического запуска CouchDB при запуске системы разработчики рекомендуют использовать runit (как подсказал мне @listochkin, читается run-it, а не r-unit :).
Создаем директорию, куда будут писаться логи:
sudo mkdir /var/log/couchdb
sudo chown couchdb:couchdb /var/log/couchdb
Создаем директории с конфигурацией для запуска couchdb:
sudo mkdir /etc/sv/couchdb
sudo mkdir /etc/sv/couchdb/log
В /etc/sv/couchdb/log/run пишем:
#!/bin/sh
exec svlogd -tt /var/log/couchdb
Опционально можно создать /etc/sv/couchdb/log/config c указанием, когда производить ротацию логов и подобного рода вешей, если дэфолты не устраивают. Формат конфига, а также дэфолты описаны в man svlogd.
Также создаем скрипт /etc/sv/couchdb/run:
#!/bin/sh
export HOME=/home/couchdb
exec 2>&1
exec chpst -u couchdb /home/couchdb/bin/couchdb
Делаем обоим скриптам chmod u+x. Затем:
sudo ln -s /etc/sv/couchdb/ /etc/service/couchdb
Через несколько секунд runit должен заметить новый сервис и запустить его. Управление:
sudo sv status couchdb
sudo sv stop couchdb
sudo sv start couchdb
Можно проверить, что после рестарта системы CouchDB запускается автоматически.
Объединение нод в кластер
Важно! Максимальный размер кластера в CouchDB по умолчанию составляет 8 нод. Чтобы изменить это, нужно отредактировать значение параметра q в секции [cluster] в etc/local.ini. Подробности см здесь.
Поднимаем три совершенно ненастроенные ноды. Если нода уже настроена, например, вы создали кластер в диалоге Setup, вот вам bash-скрипт, который все это откатывает.
Шаг 1. В /home/couchdb/etc/vm.args меняем параметры name и cookie. Кука должна быть супер секретной (pwgen 16) и одинаковой на всех нодах кластера; имена нод должны быть уникальны:
-name couchdb@10.110.2.4
-setcookie eY2chohl4siecaib
Примечание: Узнать больше про распределенный Erlang и его куки можно из заметки Мои страшные эксперименты с Erlang и gen_server.
На всех нодах говорим:
sudo sv restart couchdb
Смотрим список известных нод:
curl -X GET http://localhost:5984/_membership
Пример ответа:
{
"all_nodes": [
"couchdb@10.110.2.4"
],
"cluster_nodes": [
"couchdb@10.110.2.4",
"couchdb@localhost"
]
}
Шаг 2. На каждой ноде указываем имя пользователя и пароль, а также какой IP-адрес должна слушать нода:
curl -X PUT \
localhost:5984/_node/couchdb@10.110.2.4/_config/admins/admin \
-d '"password"'
curl -X PUT \
localhost:5984/_node/couchdb@10.110.2.4/_config/chttpd/bind_address \
-d '"0.0.0.0"' --user admin
Шаг 3. Объединяем ноды в кластер. Для этого на одной ноде для кадой ноды выполняем:
curl -X POST \
-H "Content-Type: application/json" \
http://localhost:5984/_cluster_setup \
-d '{"action":"enable_cluster","bind_address":"0.0.0.0","username'\
'":"admin","password":"password","port":5984,"remote_node":"10.'\
'110.2.5","remote_current_user":"admin","remote_current_password":'\
'"password" }' \
--user admin
curl -X POST \
-H "Content-Type: application/json" \
http://localhost:5984/_cluster_setup \
-d '{"action": "add_node", "host":"10.110.2.5", "port": "5984", '\
'"username": "admin", "password":"password"}' \
--user admin
По окончании добавления нод говорим:
curl -X POST \
-H "Content-Type: application/json" \
http://localhost:5984/_cluster_setup \
-d '{"action": "finish_cluster"}' \
--user admin
Проверяем, что ноды действительно объединились в кластер:
curl -X GET http://localhost:5984/_membership --user admin
Список all_nodes – это ноды, которые сейчас онлайн, cluster_nodes – это вообще все существующие ноды.
Работа с документами
Итак, у нас есть настроенный кластер CouchDB. Попробуем сделать с ним что-нибудь сравнительно полезное.
Создаем пользователя для доступа к БД:
curl -X PUT http://localhost:5984/_users/org.couchdb.user:afiskon \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{"name": "afiskon", "password": "secret", "roles": [],'\
' "type": "user"}'
Заметьте, что пользователей в CouchDB может создавать кто угодно, как это делается на веб-сайтах. Тут пишут, что это такая фича.
Проверяем, что пользователь действительно создался:
curl -X POST http://localhost:5984/_session \
-d 'name=afiskon&password=secret'
Ответ:
{"ok":true,"name":"afiskon","roles":[]}
Под админом создаем базу contacts (по аналогии с базой из заметки Пишем простой RESTful сервис с использованием Scotty):
curl -X PUT http://localhost:5984/contacts --user admin
Даем права для работы с этой базой пользователю afiskon:
curl -X PUT \
http://localhost:5984/contacts/_security \
-H "Content-Type: application/json" \
-d '{"admins": { "names": [], "roles": [] }, "members": '\
'{ "names": ["afiskon"], "roles": [] } }' \
--user admin
Проверяем, что пользователь теперь имеет доступ к базе:
curl -X GET http://localhost:5984/contacts --user afiskon
В ответ приходит довольно большой документ с информацией о количестве документов в базе, сколько места на диске она занимает, и тд.
Проверяем, что пользователь не может удалить базу:
curl -X DELETE http://localhost:5984/contacts --user afiskon
Для этого пользователь должен быть среди admins базы, а не members.
Создаем документ:
curl -X PUT http://localhost:5984/contacts/contact_12345 \
-d '{"name":"Alex","phone":"123"}' --user afiskon
Ответ:
{
"ok":true,
"id":"contact_12345",
"rev":"1-85bda81e2e23351d07f0f9bbcb216032"
}
Читаем документ:
curl -X GET http://localhost:5984/contacts/contact_12345 --user afiskon
Ответ:
{
"_id":"contact_12345",
"_rev":"1-85bda81e2e23351d07f0f9bbcb216032",
"name":"Alex",
"phone":"123"
}
Обновление и удаление документа выглядит так. Вы читаете весь документ, меняете его, и затем шлете запрос с указанием _rev считанного документа. Это нужно для ситуаций, когда один документ одновременно меняется несколькими клиентами. В сущности это означает, что вы всегда делаете CAS. Напомню, что в тех же Riak и Cassandra это не так. Поддержка CAS в частности означает, что поверх CouchDB можно написать распределенные транзакции.
Пример обновления документа:
curl -X PUT \
http://localhost:5984/contacts/contact_12345 \
-d '{"_rev":"1-85bda81e2e23351d07f0f9bbcb216032","name":"Alex",'\
'"phone":"456"}' \
--user afiskon
В случае конфликта получим ответ:
{"error":"conflict","reason":"Document update conflict."}
Удаление документа:
curl -X DELETE \
'http://localhost:5984/contacts/contact_12345'\
'?rev=2-972083a24122b6dc340e213ce50aa81e' \
--user afiskon
А еще можно получить id всех документов в базе:
curl http://localhost:5984/contacts/_all_docs --user afiskon
Пример ответа:
{"total_rows":1,"offset":0,"rows":[
{
"id":"contact_12345",
"key":"contact_12345",
"value":{"rev":"6-4f271d4a106be6c1286b71a861c66bf1"}
}
]}
В качестве домашнего задания можете провести такой эксперимент. Уроните одну ноду. Убедитесь, что документ можно обновить, используя только оставшиеся две ноды. Затем поднимите упавшую ноду и быстро-быстро запросите с нее документ. Убедитесь, что никакого конфликта не происходит и вы получаете последнюю ревизию.
Разумеется, рассмотреть весь API CouchDB в рамках одной статьи не представляется возможным. Подробности вы найдете в официальной документации. Там еще немало интересного про аттачи, репликацию и views, а также специальный API поиска безо всякого MapReduce.
Заключение
Несмотря на то, что в первом приближении все вроде как здорово и замечательно, тащить эту систему в продакшен я бы лично не спешил.
Во-первых, никто не знает, сколько в ней еще никем не обнаруженных багов. Никогда не забуду, как в свое время мы радостно протащили в продакшен Couchbase, а спустя какое-то время выяснили, что кластер в нем может развалиться и не собраться обратно.
Во-вторых, внимательно прочитав документацию, я выявил несколько неприятных моментов. Оказывается, документы на самом деле никогда до конца не удаляются, сколько компакшенов не запускай. То есть, со временем база будет только расти. Что мешает вычищать такие документы спустя, скажем, месяц после их удаления, не ясно. Кроме того, автоматического решардинга в CouchDB на данный момент нет, делать его придется вручную с scp и прочими плясками с бубнами. Наконец, я не обнаружил возможности указывать документам TTL, а это просто мастхев, если вы хотите класть в CouchDB сессии, коды капч, и подобного рода вещи.
Из приятных моментов хочется отметить, что CouchDB действительно пытается не терять данные. Например, он делает fsync на все записи. В отличие от него тот же Couchbase по умолчанию старается держать все в памяти, сбрасывая данные на диск лишь изредка. Впрочем, в Couchbase есть репликация, так что, возможно, это и не такая уж большая проблема. Еще из интересного – максимальный размер документа в CouchDB по умолчанию равен 64 Мб и может быть увеличен при помощи параметра max_document_size. Для сравнения, в MongoDB и Couchbase захардкожено, что докуметов размером больше 16 и 20 Мб соответственно не бывает. Также CouchDB из коробки поддерживает сжатие документов при помощи snappy и zlib, а также подписку на обновление документов при помощи change feeds, push/pull replication и возможности вызывать указанные программы при изменении документов.
Наконец, сообщество разработчиков CouchDB – пожалуй, самое открытое и дружелюбное из всех, что мне до сих пор встречались. Мейнтейнеры проекта отвечают на любые вопросы в IRC и охотно принимают посылаемые пулл реквесты (см раз, два). Если вдруг вы ищите интересный open source проект для работы над ним в свободное время, лучше CouchDB вам будет сложно что-то найти.
Таковы мои впечатления от CouchDB. А вы что скажете?