Основные криптографические алгоритмы на языке Си
Народная мудрость гласит, что правильно сделать шифрование в своем приложении крайне непросто. Свой велосипед почти наверняка будет содержать крайне неочевидные простому смертному дефекты, которые последние 20 лет исправлялись в существующих криптографических пакетах. Поэтому в любой непонятной ситуации нужно использовать готовые наработки, такие, как OpenSSL, LibreSSL, GPG или OTR. Но что делать, если для вашей конкретной задачи нет готового решения? Например, вы реализуете шифрование на уровне страниц для вашей СУБД, или вам нужно шифровать короткие сообщения, передаваемые с помощью NRF24L01 в самопальном IoT-проекте. В данном случае у вас действительно может не быть большого выбора. Но, по крайней мере, вы можете уменьшить шанс появления существенных дефектов в вашем приложении, используя проверенные временем алгоритмы и режимы шифрования.
Примечание: Подозреваю, что постоянные читатели данного блога не найдут в посте особого срыва покровов. Статья предназначена для начинающих специалистов, ну или же людей, ранее не имевших дела с криптографией. Также отмечу, что я не являюсь экспертом в криптографии, и моему мнению по вопросам из этой области не следует слишком сильно доверять.
Выбираем алгоритм хэширования
Некогда большой популярностью пользовались алгоритмы MD5 и SHA1. Но на момент написания этих строк они потеряли былую актуальность. Какие-то системы могут все еще использовать их в силу исторических причин. Однако в новом коде следует использовать более сильные алгоритмы, такие, как SHA-2 или SHA-3. Так, неплохим выбором, на практике используемым во многих современных системах, будет алгоритм SHA256, относящийся к семейству SHA-2. Ниже приведет пример хэширования блока данных при помощи этого алгоритма:
SHA256_CTX ctx;
SHA256_Init(&ctx);
uint8_t res[SHA256_DIGEST_LENGTH];
char strres[SHA256_DIGEST_STRING_LENGTH];
while(/* ... тут условие ... */) {
// здесь читаем очередной блок данных в buff, например из файла
// ....
SHA256_Update(&ctx, (uint8_t*)buff, buff_size);
}
SHA256_Final(res, &ctx);
bytesToHex(res, SHA256_DIGEST_LENGTH, strres);
printf("SHA256 = %s\n", strres);
В полной версии исходников к этому посту вы найдете реализацию не только SHA256, но и SHA384, SHA512, а также MD5 и SHA1. Все алгоритмы в данной статье были позаимствованы из исходников PostgreSQL, что хоть как-то обеспечивает их проверенность временем. Также, благодаря лицензии BSD, их можно свободно использовать как в открытых, так и закрытых проектах. Все реализации покрыты автоматическими тестами, использующие соответствующие тестовые вектора.
Выбираем алгоритм шифрования и его режим работы
Такие алгоритмы, как IDEA, Blowfish, и уж тем более DES/3DES относятся к старому поколению алгоритмов, и их не следует использовать в современных системах. Также не является надежным некогда популярный алгоритм потокового шифрования RC4. К современным и надежным шифрам можно отнести AES (он же Rijndael, читается «рэндал») и Twofish. Первый использовать намного предпочтительнее, так как, будучи стандартом, он используется практически везде и изучен экспертами вдоль и поперек.
Но одного алгоритма шифрования недостаточно, так как блочные шифры могут использоваться в различных режимах. Их много, каждый со своими сильными и слабыми сторонами. Никогда не используйте режим электронной кодовой книги (ECB). Википедия наглядно объясняет, почему:

В качестве неплохого выбора можно назвать режим сцепления блоков шифротекста (CBC), а также решим счетчика (CTR), фактически превращающий блочный шифр в потоковый:
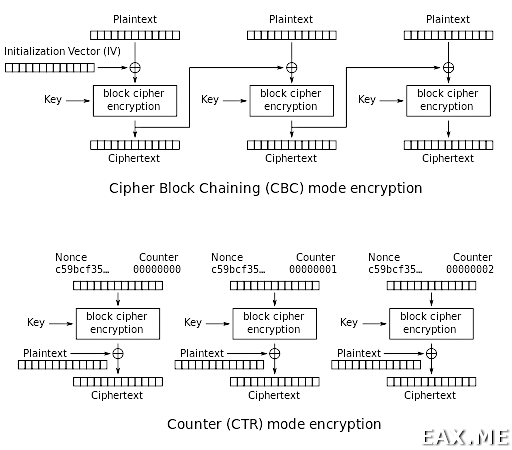
Пример использования алгоритма AES в режиме CBC:
static void
test_cbc()
{
rijndael_ctx ctx;
bool equal;
uint8_t key[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 11, 12, 13, 14, 15 };
uint8_t iv[] = { 15, 14, 13, 12, 11, 10, 9, 8,
7, 6, 5, 4, 3, 2, 1, 0 };
uint8_t data[16*3];
assert(sizeof(key) == 16);
assert(sizeof(iv) == 16);
assert((sizeof(data) % 16) == 0);
for(uint8_t i = 0; i < sizeof(data); i++)
data[i] = i;
aes_set_key(&ctx, key, sizeof(key)*8, 0);
aes_cbc_encrypt(&ctx, iv, data, sizeof(data));
equal = true;
for(uint8_t i = 0; i < sizeof(data); i++)
equal &= (data[i] == i);
assert(!equal);
aes_cbc_decrypt(&ctx, iv, data, sizeof(data));
for(uint8_t i = 0; i < sizeof(data); i++)
assert(data[i] == i);
printf("CBC test passed!\n");
}
Заметьте, что режиму CBC помимо ключа шифрования и шифруемых данных также нужен Initialization Vector (IV). Для надежного шифрования он должен быть уникальным для каждого шифруемого блока данных, в смысле никогда не повторяться. Например, если вы реализуете страничное шифрование для своей файловой системы или СУБД, то не можете просто использовать в качестве IV уникальный id страницы. Ведь в этом случае IV будет использован повторно при перезаписи страницы. Просто как пример только одного из неочевидных простым смертным дефекта. Возможное решение заключается в том, чтобы использовать неизменяемые страницы, например, хранить все в LSM-tree.
Про выбор всего остального
Криптография не ограничивается одними только блочными шифрами и алгоритмами хэширования. Для генерации ключей шифрования нужны криптографически стойкие псевдослучайные данные. Для решения этой проблемы существуют такие алгоритмы, как Fotuna и его улучшенная версия Yarrow. Для обмена ключами и подписи сообщений используется ассиметричная криптография. Здесь в дело вступают RSA, алгоритм Диффи-Хеллмана и эллиптические кривые.
Наконец, даже имея на руках все эти примитивы, их нужно уметь правильно использовать вместе. Наилучшим известным мне источником информации по этой теме является книга Брюса Шнайера и Нильса Фергюсона «Практическая криптография». Краткий пересказ основных моментов из книги вы найдете в заметке Памятка по созданию безопасного канала связи.
Пожалуй, это все, чем я хотел сегодня поделиться. Полная версия исходников к этому посту лежит в этом репозитории на GitHub. Вопросы и дополнения, как обычно, всячески приветствуются.