Тест производительности скриптов на Python
Если вы давно читаете мой блог, то можете помнить, как пару раз я говорил о Python разные неприятные вещи, дескать он медленный и памяти много кушает. При этом даже приводились различные пруфлинки. Но, откровенно говоря, нехорошо судить о языке по тому, массивы какой вложенности он поддерживает, с какой скоростью он выполняет пустой цикл из 100500 итераций и тд. Нас же интересует, как он справляется с типовыми задачами. Так что я решил провести собственный небольшой эксперимент.
1. Что и как будем измерять?
Меня в первую очередь интересуют две вещи – скорость скриптов и сколько они едят памяти. Формально говоря, сам по себе язык лишь косвенно влияет на скорость написанных с его помощью программ, или то, сколько памяти они потребляют. Но, повторюсь, нас интересуют типовые случаи. А какой интерпретатор обычно используют программисты на Python? Правильно, CPython. Вот его и будем тестировать.
Тест должен быть объективным. С одной стороны, нужно избавиться от всех возможных побочных эффектов – работы с сетью, обхода файловой системы, включенных торрентов и тп. С другой стороны, пример не должен получиться искусственным. К счастью, имеется типичная задача, которая традиционно решается с помощью скриптов и удовлетворяет обоим критериям. Это – парсинг большого файла с помощью регулярных выражений. И только попробуйте сказать, что это – нетипичная задача. Она охрененно типичная!
И последнее. Допустим, замерили мы скорость работы программы, она равна X. Это много или мало? Смотря с чем сравнивать! Сравнивать Python-скрипты будем с программами на С++ и скриптами на Perl (todo: в следующий раз не забыть про PHP). Тестировать все будем в следующем окружении:
$ python --version
Python 2.7.1
$ perl --version
This is perl 5, version 12, subversion 3 (v5.12.3) built for i386-freebsd-64int
[...]
$ gcc -v
[...]
gcc version 4.2.1 20070719 [FreeBSD]
$ uname -a
FreeBSD example.ru 8.0-RELEASE-p2 FreeBSD 8.0-RELEASE-p2 #0: ⏎
Tue Jan 5 16:02:27 UTC 2010 root@i386-builder.daemonology.net:⏎
/usr/obj/usr/src/sys/GENERIC i386
Начнем!
2. Замеряем время выполнения
Где взять большой файл, чтобы пропарсить его? Я использовал слитый из кэша Google дамп некогда известного, а нынче закрывшегося форума. Спасти удалось не все, но для наших нужд – достаточно. После объединения всех сохраненных страниц в один файл, получилось около 300 Мб HTML-кода. Сверх сложную задачу ставить нет смысла, так что попробуем просто извлечь все ник-неймы форумчан.
Решение на Python:
#!/usr/bin/env python
import sys
import re
for line in sys.stdin:
match = re.search('foobarbaz[^>]*>([a-z0-9_]+)</a></td>', line, re.I)
if match:
print match.group(1)
Здесь я не случайно использую конструкцию «for line in sys.stdin» вместо открытия файла и дальнейшего чтения из него. Как выяснилось, второй вариант работает ощутимо медленней. Следовательно, имеет место некий побочный эффект, а мы договорились их избегать.
Аналогичный скрипт, использующий предварительную компиляцию регулярного выражения:
#!/usr/bin/env python
import sys
import re
regEx = re.compile('foobarbaz[^>]*>([a-z0-9_]+)</a></td>', re.I)
for line in sys.stdin:
match = re.search(regEx, line)
if match:
print match.group(1)
Авторы книги Python в системном администрировании UNIX и Linux утверждают, что второй скрипт должен работать быстрее первого. Проверим!
Решение на Perl:
#!/usr/bin/env perl
use strict;
while(my $line = <>) {
chomp($line);
if(my @nickList =
$line =~ m{foobarbaz[^>]*>([a-z0-9_]+)</a></td>}i) {
print join "\n", @nickList;
print "\n";
}
}
Код программы на C++ можно получить путем внесения элементарных изменений в код из следующего пункта, так что здесь его я не привожу.
Чтобы быть совсем-совсем объективными, нужно в общей сложности проверить целых 6 вариантов скрипта. Два приведенных Python-скрипта нужно (1) просто запустить в интерпретаторе, (2) предварительно скомпилировать в файл .pyc и только потом запустить, а также (3) преобразовать в программу на Си с помощью Cython, собрать, используя GCC, и запустить получившийся бинарник. Мы проверим все эти варианты!
Преобразовать .py в .pyc очень просто:
python -m compileall .
С Cython чуточку сложнее. Сначала получаем код на Си:
cython python.py --embed -o python.c
Дальше можно попытаться его скомпилировать:
gcc -O2 ./python.c -o ./c_python \
-I/usr/local/include/python2.7 -L/usr/local/lib/ -lpython2.7
Вот только это не будет работать. Полезут ошибки:
./python.c: In function 'main':
./python.c:845: error: conflicting types for 'm'
./python.c:838: error: previous definition of 'm' was here
./python.c:866: warning: comparison between pointer and integer
Смотрим python.c:
#ifdef __FreeBSD__
fp_except_t m;
m = fpgetmask();
fpsetmask(m & ~FP_X_OFL);
#endif
Проблема в том, что другая переменная с именем m объявлена несколькими строками выше. Так что вторую m нужно переименовать, после чего программа успешно соберется.
Все готово, теперь можно замерять время. В юниксах для этой цели традиционно используется утилита time (не путать со одноименной командой в bash!):
/usr/bin/time -l cat BIG_FILE.TXT | ./perl.pl > /dev/null
Строго говоря, здесь замеряется время работы утилиты cat, а не нашего скрипта. Это несложно проверить, дописав в конец скрипта команду «sleep(5)». Но передать имя входного файла в качестве аргумента мы не можем в связи с описанной выше особенностью Пайтона. Условия должны быть одинаковыми для всех испытуемых!
Можно было бы использовать команду типа:
/usr/bin/time -l sh -c 'cat BIG_FILE.TXT | ./perl.pl > /dev/null'
... но тогда какую-то погрешность внесет утилита sh. К счастью, экспериментальным путем несложно проверить, что замеры с использованием и без использования sh дают практически идентичные результаты.
Все! Хватит теории. Давайте посмотрим на цифры:
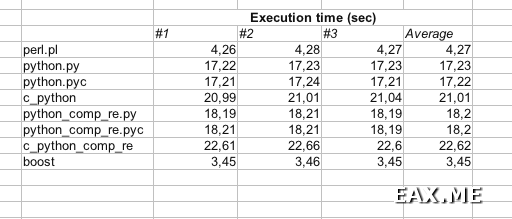
Как и следовало ожидать, быстрее всего с задачей справилась программа на C++ (я назвал ее boost). За ней с небольшим отрывом идет скрипт на Perl. А вот скрипт на Пайтоне (python.py) оказался в целых 4 раза медленней скрипта на Perl!
Что удивительно, предварительная компиляция регулярного выражения (программы с «comp_re» в имени) лишь замедляет работу скрипта. С чем это связано – не знаю. Так или иначе, товарищи Ноа Гифт и Джереми М.Джонс на этот счет нас обманули. Как и на счет того, что Python прост в изучении и интуитивно понятен даже тем, кто никогда на нем не писал. Я недавно начал на нем писать, так что можете мне поверить.
Предварительная компиляция скрипта не ускоряет его выполнения. Ну это понятно – скрипты небольшие, так что их преобразование из текста во внутреннее представление интерпретатора и так проходит быстро. Хоть не замедляет – и на том спасибо :)
А вот что вызвало у меня настоящий шок – это скорость программ, полученных при помощи Cython (имена начинаются с «c_python»). Я не знаю, почему они такие медленные.
3. Замеряем объем потребляемой памяти
Помимо времени выполнения, утилита time, запущенная с ключом -l, выводит много интересной информации. Фактически она выводит всю структуру rusage. Помимо прочего, мы можем узнать, какой максимальный объем памяти потребляла программа.
Давайте немного изменим задачу. Теперь нужно не просто извлечь из файла все имена пользователей, но и избавиться от дублей. То есть, программа должна выводить список уникальных ник-неймов. С помощью утилиты sort легко проверить, что в файле содержится всего около 3000 уникальных ников, так что можно смело хранить их в памяти. В предыдущем пункте мы выяснили, что предварительная компиляция регулярных выражений в Python только вредит, так что на этот раз обойдемся без *comp_re* скриптов. Тем более, что они не должны существенно влиять на потребление памяти.
Следует обратить внимание, что «память, используемая процессом» – штука очень относительная. Например, некоторые страницы могут попасть в своп. Кроме того – часть памяти отводится под саму программу (секция text), часть – под стек, часть – под данные (секция data). Что, если программа весит 20 Мб, но под данные выделяет только 100 Кб памяти? А если программа и данные вместе занимают 10 Кб, а под стек выделен 1 Мб? Также в Python очень активно используется разделяемая память – она считается или нет? (Кстати, к вопросу о том, зачем мне этот ваш ассемблер, если я пишу на Python.)
Я решил сделать две версии скриптов. Первая версия – нормальная, хранящая имена пользователей в памяти и выводящая только уникальные ники. Вторая версия выводит все логины (с повторами) в stdout, как в предыдущем пункте. Для обоих вариантов замеряем максимальную resident memory size и находим разность результатов. Эта разность принимается равной объему памяти, необходимому для хранения логинов.
Скрипт на Python:
#!/usr/bin/env python
import sys
import re
# Возможно, используя set вместо dict, будут получены другие результаты
# Можете считать проверку этого своим домашним заданием
nicks = dict()
if len(sys.argv) < 2:
print "Usage: " + sys.argv[0] + " <filename>"
sys.exit()
f = file(sys.argv[1])
while True:
line = f.readline()
if 0 == len(line):
break
match = re.search('foobarbaz[^>]*>([a-z0-9_]+)</a></td>', line, re.I)
if match:
nicks[match.group(1)] = 1
f.close();
for currNick in nicks.keys():
print currNick
Скрипт на Perl:
#!/usr/bin/env perl
use strict;
my %nicks;
while(my $line = <>) {
chomp($line);
if(my @nickList =
$line =~ m{foobarbaz[^>]*>([a-z0-9_]+)</a></td>}i) {
for(@nickList) {
$nicks{$_} = 1;
}
}
}
print "$_\n" for(keys %nicks);
Программа на C++, обещанная еще в предыдущем пункте:
/* (c) Alexandr Alexeev 2011 | http://eax.me/ */
#include <iostream>
#include <fstream>
#include <string>
#include <set> // <unordered_set>
#include <boost/regex.hpp>
using namespace std;
namespace std {
namespace tr1 = ::boost;
}
int main(int argc, char** argv) {
set<string> nicks;
if(argc < 2) {
cout << "Usage: " << argv[0] << " <infile>" << endl;
return 1;
}
ifstream infile;
infile.open(argv[1]);
if(!infile.is_open()) {
cout << "Failed to open '" << argv[1] << "' for reading!"
<< endl;
return 2;
}
string line;
tr1::smatch match;
tr1::regex re("foobarbaz[^>]*>([a-zA-Z0-9_]+)</a></td>");
while(infile.good()) {
getline(infile, line);
if(tr1::regex_search(line, match, re)) {
nicks.insert(match[1]);
}
}
for(
set<string>::iterator currNick = nicks.begin();
currNick != nicks.end();
currNick++) {
cout << *currNick << endl;
}
return 0;
}
Здесь мне следовало бы использовать unordered_set, оператор auto и встроенные регулярные выражения C++0x. К сожалению, поддержки всего этого нет в GCC 4.2, а скачать компилятор посвежее я поленился.
Собирается программа следующей командой:
g++ -lboost_regex -O2 boost_u.cpp -o boost_u \
-I/usr/local/include -L/usr/local/lib
Вы могли заметить, что теперь в Python-скрипте мы читаем данные из файла, а не из stdin, как делали это в пункте 2. Это не случайно. Во-первых, сейчас нас не интересует скорость скрипта. Во-вторых, мы не можем измерять параметры утилиты cat, как делали это в прошлый раз. Очевидно, что объем потребляемой ею памяти никак не связан с объемом памяти, используемой скриптами. То есть, утилита time теперь используется так:
/usr/bin/time -l ./perl_u.pl ./BIG_FILE.TXT > /dev/null
Были получены следующие результаты:
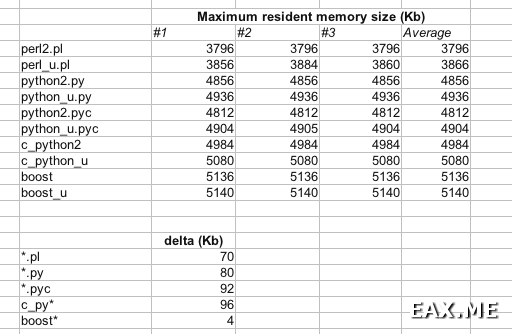
Программы с постфиксом «_u» (от «unique») хранят логины в памяти и выводят только уникальные имена.
Perl снова превзошел Python, выделив под хранение данных около 70 Кб памяти. Пайтону в свою очередь понадобилось 80-95 Кб. А вот память, использованную программой на C++, похоже, просто не удалось замерить! Очевидно, что 3000 ников, имеющих среднюю длину 8 символов, никак не умещаются в 4 Кб памяти. Даже если в GNU-версии STL контейнер set использует для хранения строк какое-то хитрое дерево символов. Применение алгоритма сжатия также маловероятно. Скорее всего, программа в обоих случаях зарезервировала немного памяти на будущее, чтобы сократить число системных вызовов.
Интересно, что в данном случае программы на C++ потребляли больше памяти, чем скрипты на Perl или Python. Но не спешите радоваться – для более крупных программ такого происходить не будет. Кроме того, можно поиграться с флагами компилятора, чтобы сократить объем используемой памяти.
4. Выводы
Каждый способен сделать собственные выводы из этой заметки. Для себя я сделал следующие:
- Python – медленный язык, потребляющий много памяти. Но стоит присмотреться повнимательнее к PyPy;
- Предварительная компиляция .py скрипта в .pyc не ускоряет скрипт, но позволяет интерпретатору быстрее его пропарсить. При этом скрипт потребляет немного меньше оперативной памяти (внимательно смотрим последнюю картинку);
- Cython ощутимо тормозит программу, но позволяет запускать ее в среде без установленного интерпретатора Python. Объем потребляемой программой памяти увеличивается им незначительно;
- Переписав программу с Perl на C++, можно ускорить ее на 20-25%;
- Переписав программу с Python на C++, можно ускорить ее в 5 раз;
- Скрипт на Perl действительно требует в 2-3 раза больше памяти, чем аналогичная программа на C++. Если не ошибаюсь, именно это прямым текстом и написано в Learning Perl;
- Скрипт на Perl имеет в 2-3 раза меньше строк когда, чем аналогичная программа на C++ и примерно столько же строк, сколько в аналогичном скрипте на Python;
- Утилита time – хороший, годный инструмент. И не нужно извращаться с системными функциями, ассемблерной инструкцией rdtsc и так далее. В ОС уже все предусмотрено.
Соглашаться с этими выводами или нет – дело ваше.
5. Дополнительная инфа
Другие материалы, посвященные производительности Пайтона:
- http://mocksoul.livejournal.com/5789.html – тест производительности Java, C++, Python, Perl и PHP;
- http://www.vitalik.com.ua/rails/perl-python-ruby-php.html – сравнение Perl, Python, Ruby и PHP;
- http://begemotov.net/creator/programming/ozarenie-ili-piton-mat-ego/ – о количестве памяти, потребляемой Пайтоном;
- http://nobu.aoizora.org/?p=1068 – особенность сборщика мусора, приводящая к нехватки памяти;
- http://redplait.blogspot.com/2011/05/beautiful-code.html – критика Python;
- http://redplait.blogspot.com/2011/08/python-3.html – и еще немного критики;
- http://attractivechaos.wordpress.com/2011/...benchmark-analyses/ – очень интересное сравнение производительности Си, Java, C#, D, Go, Perl, Python, Lua, R, JavaScript и Ruby;
- http://speed.pypy.org/ – производительность PyPy по сравнению с CPython;
- http://koldunov.net/?p=417 – способ ускорения скриптов на Python за счет использования оптимизированных модулей;
- http://www.perl.com/pub/2001/06/27/ctoperl.html – здравые мысли на тему, почему не нужно пытаться ускорить скриптовые языки путем их трансляции в код на C/C++;
- http://www.scipy.org/PerformancePython – ускорение Python скриптов путем inline-использования языков Си и Fortran, а также Pyrex (который теперь Cython);
- http://habrahabr.ru/blogs/python/124388/ – об оптимизации скриптов на Python, статья Владислава Степанова (написана после публикации этой заметки);
- http://habrahabr.ru/blogs/python/124862/ – ускорение Python скриптов с использованием Cython, статья Юрия Блинкова (написана после публикации этой заметки);
Дополнение: Относительно двух последних статей. К моему великому сожалению, в обоих случаях сравнивается скорость Python скрипта после оптимизации со скоростью того же скрипта до оптимизации. Допустим, скрипт стал в 500 раз быстрее. Спрашивается – насколько это быстрее/медленнее по сравнению с реализацией на C++ или Perl? Также ничего не говорится по поводу используемых объемов памяти.
Дополнение: А еще недавно я застукал BitTorrent-клиент Deluge (написанный угадайте-на-чем) за поеданием порядка 900 Мб оперативной памяти:
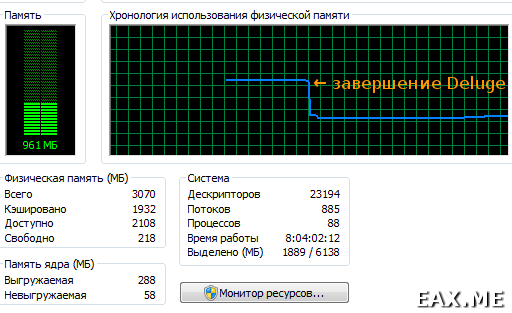
Проблема проявляется только после длительной работы Deluge. В связи с этим я подозреваю, что винить в прожорливости программы следует garbage collector, который, по всей видимости, не справился со своей работой.
Как обычно, любые комментарии приветствуются. Только, пожалуйста, воздержитесь от воплей типа «В реальных задачах Питон в 20 раз быстрее этого вашего Пёрла, просто вы мерить не умеете» или высокоумных фраз в стиле «На практике 90% времени программы работают с диском и сетью, а не обрабатывают данные, да и память нынче дешевая». Можете доказать первое – пишите статью. Последнее является слабым утешением для тех, кто занимается именно вычислениями.