Как спроектировать схему базы данных
13 марта 2014
Время от времени я заглядываю на Toster.ru и иногда даже отвечаю там на вопросы. Чаще всего люди спрашивают две вещи — как стать программистом и как правильно спроектировать схему базы данных. Мне лично кажется очень странным, что так много людей задают последний вопрос. Мне почему-то всегда казалось, что это такая простая вещь, которую умеют вообще все. Но, раз так много людей интересуются, здесь я постараюсь дать достаточно развернутый и в то же время краткий ответ.
Дополнение: Также вас могут заинтересовать заметки Начало работы с PostgreSQL, Потоковая репликация в PostgreSQL и пример фейловера, Некоторые интересные отличия PostgreSQL от MySQL и Обратная совместимость и изменение схемы базы данных.
Я предполагаю, что SQL вы знаете. То есть, объяснять, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, не требуется. Если это не так, боюсь, я вынужден отправить вас к соответствующей литературе. Благо, ее сейчас очень много.
Рисуем диаграмму
Допустим, требуется спроектировать схему базы данных, в которой хранится информация о музыкальных исполнителях, альбомах и песнях. На начальном этапе, когда у нас еще совсем ничего нет, удобно начать с рисования диаграммы будущей схемы. Можно начать с наброска ручкой на листе бумаги, можно сразу взять специализированный редактор. Их сейчас очень много, все они устроены довольно похожим образом. При подготовке этой заметки я воспользовался DbSchema. Это платная программа, но мне кажется, что она стоит своих денег. К тому же, в нормальных компаниях обычно оплачивают стоимость софта, необходимого для работы. Триал у DbSchema, если что, составляет две недели.
Нарисовать следюущую диаграмму заняло у меня порядко десяти минут:
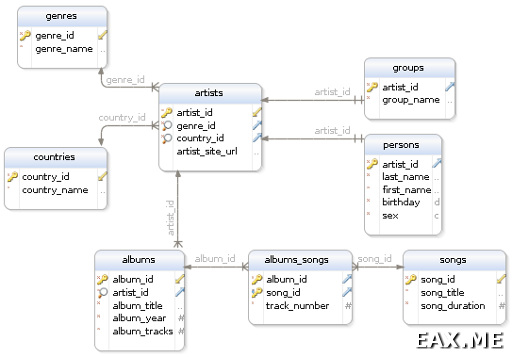
Если раньше вам не доводилось работать с такими диаграммами, не пугайтесь, тут все просто. Прямоугольнички — это таблицы, строки в прямоугольничках — имена столбцов, стрелочками обозначаются внешние ключи, а ключиками — первичные ключи. При желании тут можно разглядеть даже индексы, типы столбцов и обязательность их заполнения (null / not null), но для нас сейчас это не так важно.
Дополнение: Аналогичную диаграмму можно построить при помощи открытого инструмента PlantUML.
Генерируем SQL и скармливаем его СУБД
Нетрудно заметить, что данная диаграмма легко отображается в код для создания схемы базы данных на языке SQL. В DbSchema сгенерировать SQL можно, сказав Schema → Generate Schema and Data Script. Затем полученный скрипт можно скормить используемой вами СУБД:
Я использовал PostgreSQL. Информацию о том, как установить эту СУБД, вы найдете в этой заметке.
Итак, чем же я руководствовался при проектировании схемы?
Нормальные формы
Процесс устранения избыточности и ликвидации противоречивости базы данных называется нормализацией. Выделяют так называемые нормальные формы, из которых на практике редко кто помнит больше первых трех.
Грубо говоря, таблица находится в первой нормальной форме (1НФ), если на пересечении любой строки и любого столбца в таблице находится ровно одно значение. В современных РСУБД это условие всегда выполняется. Даже если СУБД поддерживает множества или массивы, на пересечении строки и столбца хранится ровно одно значение типа множество или массив. Но в таблице (user varchar(100), phone integer) не может быть строки alex - 1234, 5678. В 1НФ может быть только две сроки — alex - 1234 и alex - 5678.
Вторая нормальная форма (2НФ) означает, что таблица находится в первой нормальной форме, и каждый неключевой атрибут неприводимо зависит от значения первичного ключа. Неприводимость означает следующее. Если первичный ключ состоит из одного атрибута, то любая функциональная зависимость от него неприводима. Если первичный ключ является составным, то в таблице не может быть атрибута, значение которого однозначно определяется значением подмножества атрибутов первичного ключа.
Таблица находится в третьей нормальной форме, если она находится в 2НФ и ни один неключевой атрибут не находится в транзитивной функциональной зависимости от первичного ключа. Например, рассмотрим таблицу (employee varchar(100) primary key, department varchar(100), department_phone integer). Очевидно, что она находится в 2НФ. Но телефон отдела находится в транзитивной функциональной зависимости от имени сотрудника, так как сотрудник однозначно задает отдел, а отдел однозначно задает телефон отдела. Для приведения таблицы в 3НФ нужно разбить ее на две таблицы — employee - department и departmnet - phone.
Легко видеть, что нормализация уменьшает избыточность базы данных и препятствует внесению случайных ошибок. Например, если оставить таблицу из последнего примера в 2НФ, то можно по ошибке прописать одному и тому же отделу разные телефоны. Или рассмотрим компанию с пятью отделами и 1000 сотрудниками. Если у отдела поменялся номер телефона, то для его обновления в базе данных в случае 2НФ потребуется просканировать 1000 строк, а в случае с 3НФ только пять.
Как я уже отмечал, есть и более строгие нормальные формы, но на практике обычно используются только первые три.
Отношение один ко многим
На приведенной диаграмме можно заметить, что каждый исполнитель относится к какой-то стране, и каждый альбом принадлежит какому-то исполнителю. Это и есть отношение один ко многим. Например, к одной стране относится множество исполнителей, и каждый исполнитель может иметь множество альбомов. Но приведенная схема, например, запрещает одному альбому принадлежать множеству исполнителей. Хотя в реальной жизни, конечно, это возможно, например, в случае со сборниками.
Для моделирования такого типа отношения в каждом альбоме указывается id исполнителя, и в каждом исполнителе указывается id страны. Понятное дело, мы не просто пишем туда какую-то циферку, а возлагаем ответственность по контролю ссылочной целостности на нашу СУБД:
Это часто оказывается большим сюрпризом для тех, кто всю жизнь работал с MySQL и его бэкендом MyISAM, который так не умеет. Я не вижу причин не проверять ссылочную целостность, если только вы не пишите супер-пупер высоконагруженный проект, у которого исполнители хранятся на одном сервере, а альбомы — на другом. В противном случае вас ждет много часов увлекательной отладки вашего приложения в ночь с субботы на воскресенье, потому что как-то так получилось, что кто-то создал альбом с несуществующим исполнителем.
Жанры и страны в приведенной схеме иногда еще называют «словарями». Это сравнительно небольшие таблицы, состоящие из двух столбцов — id и названия. Если, например, мы захотим переименовать страну Russia в Russian Federation, нам придется поменять всего лишь одну строчку в таблице countries, а не править кучу строк в таблице artists, что может привести к очень большому количеству дисковых операций. Кроме того, если требуется отобразить в диалоге создания нового исполнителя выпадающий список с выбором страны, нам не придется делать дорогих группировок по таблице artists, достаточно сделать простую выборку из countries.
Отношение многие ко многим
Один альбом, как правило, содержит множество песен. Кроме того, нет веских причин, почему одна песня не может находится сразу в нескольких альбомах. Здесь мы имеем место с типичным отношением многие ко многим.
Оно моделируется путем введения дополнительной таблицы. В нашем примере эта таблица называется albums_songs. Первичный ключ в этой таблицы состоит из двух внешних ключей — album_id и song_id. Теперь нетрудно с помощью пары join’ов получить все песни, входящие в данный альбом или все альбомы, в которые входит заданная песня. Кроме того, ничто не мешает завести в связующей таблице дополнительные столбцы. Например, столбец, хранящий номер трека, под которым песня входит в заданный альбом.
На практике связаны могут быть не две, а три и более таблиц. Например, некий пользователь сделал некий заказ, выбрав указанный способ оплаты, адрес и способ доставки — пожалуйста, пять таблиц как с куста.
Отношение родитель-потомок (или общее-частное)
Исполнители могут быть разных типов. Это может быть отдельно взятый(ая) певец/певица, или же группа. У всех исполнителей, независимо от конкретного типа, есть что-то общее. Например, страна, адрес официального сайта и так далее. Но кроме того, есть некоторые свойства, характерные только для данного типа. У певицы явно нет никакого названия группы, а у группы нет имени, фамилии и пола. Аналогичная ситуация возникает, скажем, если у вас есть сотрудники, занимающие различные должности и свойства сотрудников зависят от занимаемых должностей.
Один из способов моделирования такой ситуации заключается в введении по отдельной таблице на каждый из возможных подтипов. В приведенном примере это таблицы groups и persons. В качестве первичного ключа в каждой из этих таблиц используется artist_id, первичный ключ родительской таблицы artists. Кто-то при использовании такой схемы предпочитает добавить в родительскую таблицу столбец type, но, строго говоря, он является избыточным. Недостаток этого метода заключается в том, что можно создать исполнителя, являющегося как группой, так и человеком одновременно.
Есть и другие подходы. В PostgreSQL, например, есть наследование таблиц, предназначенное для решения как раз такой вот проблемы. Если вы работаете с PostgreSQL, нет причин не использовать этот механизм. Кто-то предпочитает ввести одну таблицу для всех типов с дополнительным столбцом type. Если некий столбец не имеет смысла для заданного типа, в него пишется null. Но это, как вы можете подозревать, не очень-то удобно, если у вас 10 типов, каждый из которых имеет по дюжине столбцов, характерных только для этого типа, а также парочку собственных подтипов. Кроме того, можно опрометчиво реализовать смену типа, как простое обновление столбца type, и получить массу интереснейших эффектов.
Что еще нужно принять во внимание
Принцип при моделировании других отношений тот же. Например, один человек имеет двух родителей и при этом один человек может иметь сколько угодно детей. Казалось бы, связь 2:N, этого мы не проходили. На самом деле, это просто две связи 1:N. Вводим столбцы mother_id, father_id и вперед. Да, связь в рамках одной таблицы, ну и что?
Иногда на практике можно столкнутся с древовидными структурами. На самом деле, это то же самое отношение один ко многим, один родитель имеет много потомков. В общем, вводится столбец parent_id, куда пишется «внешний» первичный ключ из этой же таблицы. В корневом элементе устанавливается parent_id равный null. Главное при работе с этим хозяйством — не наплодить случайно циклов.
В общем, все, что нужно, это немного здравого смысла.
Также при проектировании схемы базы данных нужно уделять внимание индексам. Тут все сильно зависит от конкретной СУБД, поддерживает ли она составные индексы, частичные индексы, функциональные индексы, bitmap scans и так далее. Кое-что по этой теме я писал здесь, а вообще — курите мануалы по вашей СУБД. Также за кадром остались вьюхи, триггеры и многое другое.
В высоконагруженных проектах в целях оптимизации иногда прибегают к денормализации, то есть, процессу, обратному нормализации. Действительно, в некоторых случаях намного эффективнее держать все в одной таблице, чем делать несколько десятков джоинов. Иногда данные распределяют между несколькими серверами. Понятно, что в этом случае ссылочная целостность никем не проверяется и может быть случайно нарушена. Сплошь и рядом базы данных содержат в себе некоторую избыточность. Например, стоимость заказа можно однозначно определить, сложив стоимость товаров в корзине. Но иногда эффективнее хранить уже посчитанную стоимость, особенно если речь идет не об одной корзине, а о месячном отчете по всей системе. Иногда избыточность добавляется, чтобы данные можно было починить в случае программных ошибок. Например, все критичные операции сопровождаются записью в таблицу-журнал.
Ну и нельзя не отметить, что приведенный здесь пример с исполнителями и альбомами довольно игрушечный. В реальных условиях база данных может запросто содержать сотню таблиц, каждая из которых имеет многие десятки столбцов и миллионы строк. Или, например, одну таблицу, имеющую пару сотен столбцов. Примите также во внимание, что схема базы данных имеет свойство довольно часто меняться, что, разумеется, приводит к необходимости мигрировать данные, и вы получите более-менее правдоподобную картину того, с чем на самом деле вам предстоит столкнуться.
Заключение
Все приходит с опытом. Самостоятельно спроектируйте две-три схемы, и картинка сама сложится у вас в голове. В качестве ДЗ можете спроектировать базу данных блога, интернет-магазина или базу с сотрудниками компании, их должностями и контактами. Отталкивайтесь от задачи. Учитывайте, кто и какие действия будет совершать с базой данных. Например, с базой интернет-магазина работают не только клиенты, но и, например, отдел доставки.
Проект для DbSchema, а также сгенерированный из него SQL, вы можете скачать здесь. Как всегда, если у вас есть вопросы или дополнения, не стесняйтесь писать их в комментариях.
Метки: Разработка, СУБД.
Вы можете прислать свой комментарий мне на почту, или воспользоваться комментариями в Telegram-группе.