Внутренности PostgreSQL: страницы и кортежи
20 июня 2022
Недавно мы научились напрямую работать с таблицами PostgreSQL из расширений на C. Предлагаю капнуть чуть глубже и разобраться, как PostgreSQL физически хранит данные на диске. Стоит сказать, что представленный материал не претендует на новизну. Вопрос этот хорошо описан в более чем в одном источнике, не исключая официальной документации на PostgreSQL. Однако мне хотелось бы иметь собственную шпаргалку, акцентирующую внимание на наиболее интересных мне лично моментах.
Создадим новую таблицу и запишем в нее какие-то данные:
"id" SERIAL PRIMARY KEY NOT NULL,
"name" NAME NOT NULL,
"phone" INT NOT NULL);
INSERT INTO phonebook ("name", "phone")
VALUES ('Alice', 123), ('Bob', 456), ('Charlie', 789);
Спрашивается, где эти данные будут лежать на диске? За ответом обратимся к таблице системного каталога pg_class:
-[ RECORD 1 ]-------+----------
oid | 16393
relname | phonebook
relnamespace | 2200
reltype | 16395
reloftype | 0
relowner | 10
relam | 2
relfilenode | 16393
...
Колонка relfilenode хранит имя файла с данными на диске. На самом деле, это не совсем правда, но на первое время сгодится. Детали мы рассмотрим ниже по тексту. Кроме того, на самом деле колонка имеет не строковый тип, а целочисленный тип Oid.
Имя директории, где PostgreSQL хранит все данные, можно получить так:
data_directory
----------------------------------
/Users/eax/pginstall/data-master
В некоторых источниках этот каталог еще называется PGDATA. Здесь PostgreSQL был собран из исходников и установлен в ~/pginstall/, поэтому такой путь. У вас он наверняка будет другим.
Теперь мы обладаем всей информацией, чтобы найти файл:
/Users/eax/pginstall/data-master/base/16384/16393
Каталог base — это общий каталог для всех баз данных кластера, а 16384 — это Oid базы данных, к которой относится таблица:
You are now connected to database "eax" as user "eax".
=# SELECT oid FROM pg_database where datname = 'eax';
-[ RECORD 1 ]
oid | 16384
Найденные нами данные в терминологии PostgreSQL называются кучей (heap). Так называются данные, непосредственно хранящиеся в таблицах. Помимо кучи еще есть, к примеру, индексы и WAL.
Файл 16393 называется сегментом. Максимальный размер сегмента задается при компиляции параметром --with-segsize= и по умолчанию равен 1 Гб. Это значение выбрано для того, чтобы PostgreSQL мог работать на ФС не поддерживающих файлы больше 1 Гб. Когда объем данных в сегменте превышает заданный порог, создаются сегменты 16393.1, 16393.2 и так далее. Стоит сказать, что какой-нибудь ext4 без проблем поддерживает файлы до 16 Тб. А вот работа со множеством мелких файлов может приводить к заметным накладным расходам. Поэтому в современных реалиях --with-segsize= следует увеличивать.
Чтобы узнать, с какими параметрами был собран используемый вами пакет PostgreSQL, используйте команду pg_config --configure.
Структура сегмента выглядит так:
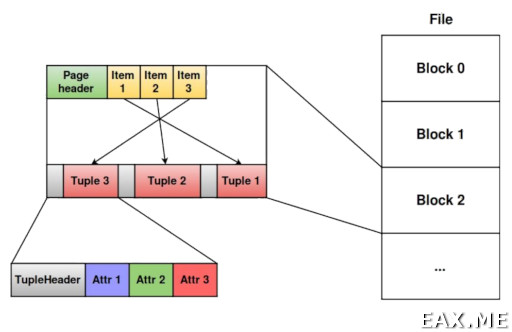
Сегмент разбит на страницы, или блоки, фиксированного размера. Размер страницы также задается при компиляции, параметром --with-blocksize=. Значение по умолчанию составляет 8 Кб. В коде это значение объявляется, как макрос BLCKSZ. Сколько страниц хранит один сегмент задается макросом RELSEG_SIZE.
Недавнее исследование, проведенное Tomas Vondra, свидетельствует о том, что для многих нагрузок размер страницы по умолчанию не оптимален. Для OLTP выгоднее использовать страницы размером 4 Кб, а для OLAP — размером 16 Кб или 32 Кб. Впрочем, проведенные бенчмарки следует воспринимать с некоторой долей скептицизма, поскольку они никак не учитывают механизм TOAST и множество других факторов.
Страница состоит из заголовка фиксированного размера, массива переменного размера из элементов ItemIdData, свободного пространства (free space) и непосредственно кортежей. Новые элементы ItemIdData записываются в начало страницы, а новые кортежи — в конец. То есть, они занимают свободное пространство страницы, идя навстречу друг другу. В индексах используется такая же структура с тем отличием, что в конце страницы есть специальная область (special space). Это своего рода расширение заголовка. Например, B-Tree хранит в специальной области указатели на дочерние страницы.
Заголовку соответствует структура PageHeaderData размером 24 байта:
{
PageXLogRecPtr pd_lsn;
uint16 pd_checksum;
uint16 pd_flags;
LocationIndex pd_lower;
LocationIndex pd_upper;
LocationIndex pd_special;
uint16 pd_pagesize_version;
TransactionId pd_prune_xid;
/* ... */
} PageHeaderData;
Рассмотрим каждое из полей:
- pd_lsn [8 байт] — указатель (смещение) в WAL на первый байт после последней записи, менявшей данную страницу;
- pd_checksum [2 байта] — контрольная сумма страницы;
- pd_flags [2 байта] — различные флаги. Например, когда на странице не удается найти свободное место, проставляется флаг-подсказка PD_PAGE_FULL;
- pd_lower [2 байта] — смещение начала свободного пространства;
- pd_upper [2 байта] — смещение конца свободного пространства;
- pd_special [2 байта] — смещение начала специальной области;
- pd_pagesize_version [2 байта] — версия страницы и ее размер. В настоящее время используется версия 4. Размер страниц в PostgreSQL должен быть кратен 256-и, что позволяет кодировать его одним байтом;
- pd_prune_xid [4 байта] — поле-подсказка, смысл которого на данном этапе нам не особо важен. В индексах это поле вовсе не используется;
Контрольные суммы включаются при создании базы данных командой initdb. Для этого нужно указать флаг --data-checksums. По умолчанию, если явно не указать этот флаг, контрольные суммы выключены. Узнать, включены ли контрольные суммы, можно либо командой pg_controldata каталог_pgdata, либо сказав SHOW data_checksums в psql. О том, как включить или выключить контрольные суммы в существующем кластере, в том числе при использовании репликации, читайте в документации на утилиту pg_checksums. На момент написания этих строк контрольные суммы нельзя включить на работающем кластере, но разработка этого функционала ведется.
PostgreSQL считает страницу, состоящую из одних нулей, корректной станицей, безотносительно значения контрольной суммы. Таким образом, система не устойчива к ошибкам в софте и железе, приводящим к обнулению данных. В этом легко убедиться, если аккуратно остановить СУБД с помощью pg_ctl ... stop, затем занулить страницу командой dd if=/dev/zero of=путь_к_сегменту bs=8K count=1, и снова запустить СУБД. Данные просто тихо пропадут, никакого предупреждения в логах не будет.
Следом за заголовком страницы идет массив из ItemIdData:
{
unsigned lp_off:15, /* смещение кортежа */
lp_flags:2, /* состояние: элемент свободен,
элемент используется,
плюс пара состояний для HOT
(см ниже) */
lp_len:15; /* размер кортежа */
} ItemIdData;
Спрашивается, для чего нужен этот массив? Дело в том, что кортежи имеют переменный размер, а также могут перемещаться внутри страницы во время VACCUM. Но нам нужно как-то ссылаться на кортежи из тех же индексов. Так вот, ссылка идет не на сам кортеж, а на номер страницы и индекс массива ItemIdData[]. В коде такая ссылка называется ItemPointer. Во время VACUUM система блокирует страницу, удаляет и перемещает кортежи, тем самым освобождая свободное пространство, должным образом меняет все ItemIdData, и снимает блокировку. Все ItemPointer’ы при этом остаются корректными.
Fun fact! Выполните запрос SELECT ctid, * FROM phonebook. Здесь ctid — это системная колонка с типом tid, и это ни что иное, как ItemPointer на соответствующую строку. Системные колонки можно использовать так же, как и обычные, в частности, в WHERE-условиях.
Кортежи в PostgreSQL неизменяемые, если не считать заголовка (о нем ниже). Когда вы обновляете строку в таблице, на самом деле создается новая версия кортежа. Это необходимо для реализации MVCC. Хоть строка и была изменена в текущей транзакции, другая транзакция может продолжать видеть старую версию строки. По тем же причинам, когда вы что-то удаляете, на самом деле данные остаются на диске. Физически данные могут быть удалены только тогда, когда не осталось активных транзакций, способных их видеть. Удалением кортежей занимается VACUUM.
Кортеж состоит из заголовка размером 23 байта, битовой маски NULL-элементов (null bitmap), и непосредственно значений атрибутов. Заголовку соответствует структура HeapTupleHeaderData. В коде она объявлена несколько запутанно. Рассмтроим структуру в упрощенном виде:
{
TransactionId t_xmin;
TransactionId t_xmax;
union
{
CommandId t_cid;
/* ... */
} t_field3;
} HeapTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
/* ... */
} t_choice;
ItemPointerData t_ctid;
uint16 t_infomask2;
uint16 t_infomask;
uint8 t_hoff;
/* ... */
};
Смысл этих полей следующий:
- t_xmin [4 байта] — идентификатор транзакции (XID), создавшей кортеж;
- t_xmax [4 байта] — XID транзакции, удалившей кортеж;
- t_cid [4 байта] — идентификатор команды внутри транзакции (CID), создавшей и/или удалившей кортеж;
- t_ctid [6 байт] — ItemPointer на более новую версию кортежа;
- t_infomask2 [2 байта] — 11 бит занимает количество атрибутов в кортеже, остальные биты используются под флаги;
- t_infomask [2 байта] — флаги. Например, если в кортеже содержатся NULL-элементы, проставляется флаг HEAP_HASNULL;
- t_hoff [1 байт] — размер заголовка вместе с null bitmap и с учетом выравнивания;
Первые три поля необходимы для реализации MVCC. По ним СУБД может понять, видит ли транзакция заданный кортеж или не видит.
Fun fact! Выполните запрос SELECT xmin, xmax, cmin, cmax, * FROM phonebook. Объясните результат (см документацию).
Поле t_ctid указывает на более новую версию кортежа. Кроме того, t_ctid используется в оптимизации Heap Only Tuples (HOT). Допустим, у вас есть таблица, и по ней построены индексы. Когда вы обновляете строку, не изменяя ни одно из проиндексированных полей, HOT позволяет избежать дорогого обновления индексов. В t_infomask2 проставляется флаг HEAP_HOT_UPDATED, а поле t_ctid ссылается на более новый кортеж. У последнего проставляется флаг HEAP_ONLY_TUPLE. Это позволяет индексам найти более новый кортеж, хоть он и не был проиндексирован. Кортеж, на который идет ссылка, в свою очередь может ссылаться на другой кортеж. Это называется HOT-цепочка (HOT chain).
Если в новом кортеже обновлены проиндексированные атрибуты, или если кортеж не удается поместить в ту же страницу, что и старый, HOT не сработает. Поле t_ctid старого кортежа будет ссылаться на более новый, но флаг HEAP_HOT_UPDATED проставлен не будет. Это будет конец HOT-цепочки, и в индексах будут созданы новые записи. Почему HOT-цепочка ограничена одной страницей? Так сделано по ряду причин. Этим мы избегаем создания слишком длинных цепочек. Кроме того, мы не обязаны вечно хранить кортеж в HOT-цепочке. Благо, в ItemIdData предусмотренны дополнительные состояния, позволяющие ссылаться на другие ItemIdData. Но ItemIdData уже не мог бы ссылаться за пределы страницы.
На 11-и битах под количество атрибутов в t_infomask2 хочется остановится поподробнее. Может создаться ошибочное впечатление, что кортеж может содержать 2048 или, быть может, 2047 атрибутов. На самом деле, это число меньше. Максимальное число атрибутов в кортеже, а также столбцов в таблице, ограничено значениями MaxTupleAttributeNumber и MaxHeapAttributeNumber соответственно, или 1664 и 1600 штуками. Это разные значения, потому что кортеж не обязательно принадлежит таблице. Например, когда вы JOIN’ите десять таблиц, результат также хранится в кортеже.
Fun fact! В PostgreSQL совершенно законно иметь таблицу с нулем столбцов.
В поле t_infomask, помимо прочего, хранятся так называемые hint bits. Это флаги, говорящие о том, что транзакция, создавшая или удалившая кортеж, завершилась успешно или не успешно. Это своего рода кэш, позволяющий быстрее производить проверку видимости. Без hint bits приходилось бы постоянно проверять состояние транзакций t_xmin и t_xmax, а это сравнительно дорогое хождение во внешнюю структуру CLOG. Если известно, что кортеж виден всем транзакциям, говорят, что он заморожен. У такого кортежа проставляется флаг HEAP_XMIN_FROZEN. На самом деле, это не отдельный флаг, а особое сочетание флагов.
Флаги эти примечательны тем, что их могут проставлять читающие транзакции. При этом в буферном кэше страница с кортежем помечается, как грязная, и требующая записи на диск. Логично, ведь содержимое страницы поменялось. Как результат, можно наблюдать, как СУБД интенсивно пишет в диск, хотя, казалось бы, исполняет исключительно SELECT-запросы. Такая вот особенность.
С битовыми масками и полем t_hoff, думаю, все должно быть понятно. Если бит соответствующего атрибута установлен в 1, значит в атрибуте записан NULL, и на диске его нет. Характерно, что с учетом выравнивания HeapTupleHeaderData занимает не 23, а 24 байта. Это означает, что вы можете иметь до 8-и NULL-able атрибутов бесплатно. Выравнивание влияет и на атрибуты. Например, атрибут с типом BIGINT пишется так, чтобы его адрес был кратен 8-и байтам. PostgreSQL хранит атрибуты в порядке, указанном пользователем. То есть, СУБД не пытается оптимизировать порядок с учетом выравнивания.
Таким образом, две, казалось бы, одинаковые таблицы:
CREATE TABLE good(i1 INT, i2 INT, b1 BIGINT);
… будут занимать разное место на диске. С порядком атрибутов в индексах принцип тот же. Впрочем, детали могут зависеть от платформы и, потенциально, от компилятора, его версии, а также использованных флагов оптимизации. В большинстве задач слишком уж сильно беспокоиться по данному поводу, по видимому, не стоит.
Стоит однако быть в курсе, что формат данных на диске в PostgreSQL является платформо-зависимым. В общем случае вы не можете просто скопировать файлы базы данных с одной платформы на другую. По тем же причинам потоковая репликация между разными платформами в общем случае не будет работать.
Остается один вопрос. Вот нашел PostgreSQL кортеж. Это по сути заголовок, плюс какие-то байты. Откуда PostgreSQL знает, как интерпретировать эти байты? За этой информацией СУБД обращается к таблице каталога pg_attribute. В качестве домашнего задания предлагаю вам написать SELECT запрос, выводящий результат, аналогичный выводу \d phonebook. Подсказка: вам понадобится сделать JOIN с таблицей pg_type. В качестве задания со звездочкой предлагаю ответить на следующий вопрос. Как вы думаете, что происходит с кортежами после ALTER TABLE? Например, что будет, если добавить колонку email и удалить phone? Зависит ли результат от того, являются ли колонки NULL-able или нет?
Это все, о чем я хотел рассказать в данном посте, однако это далеко не вся картина. За кадром еще остались free space map, visibility map, TOAST, WAL, и многие другие вопросы. В качестве источников дополнительной информации можно порекомендовать книги The Internals of PostgreSQL за авторством Hironobu Suzuki и PostgreSQL 14 изнутри за авторством Егора Рогова. Обе книги распространяются бесплатно в электронном виде.
Дополнение: В продолжение темы смотри Простой пример использования pageinspect, Внутренности PostgreSQL: механизм TOAST, Внутренности PostgreSQL: разделяемые буферы и далее по ссылкам.
Метки: PostgreSQL, Алгоритмы, СУБД.
Вы можете прислать свой комментарий мне на почту, или воспользоваться комментариями в Telegram-группе.