Поиск по географическим данным при помощи PostGIS
4 сентября 2017
PostGIS — это географическая информационная система, или ГИС (geographic information system, GIS), реализованная в виде расширения к PostgreSQL. ГИС позволяет хранить пространственные или географические данные, такие, как точки, ломаные линии и полигоны, производить по ним эффективный поиск, а также выполнять с ними другие операции. В общем, можно написать убийцу Google Maps и Яндекс.Карт :) Давайте же попробуем разобраться, как пользоваться этой штукой.
Примечание: Пользуясь случаем, я хотел бы поблагодарить Алексея Палажченко и Стаса Кельвича за то, что помогли мне разобраться в некоторых не самых очевидных моментах касаемо работы PostGIS.
Установка PostGIS
Поскольку PostGIS является расширением к PostgreSQL, для работы ему, очевидно, нужен установленный PostgreSQL. Установка и настройка этой СУБД ранее рассматривалась в заметке Начало работы с PostgreSQL. Поскольку в ней предполагалось, что в качестве операционной системы используется Ubuntu Linux, далее для определенности я также буду исходить из этого предположения. Отличия для других операционных систем и дистрибутивов Linux будут минимальными.
Итак, нам понадобятся следующие пакеты:
Подключаемся к PostgreSQL под пользователем postgres:
… и говорим:
create extension postgis;
Поздравляю, PostGIS установлен!
Немного матчасти
На случай, если вам когда-нибудь придется заполнять базу геоданных с нуля, делается это как-то так:
SELECT AddGeometryColumn('my_points', 'point', 4326, 'POINT', 2);
INSERT INTO my_points (name, point)
VALUES ('Центр Москвы',
ST_GeomFromEWKT('SRID=4326;POINT(37.617635 55.755814)'));
В приведенным примере процедура AddGeometryColumn добавляет в таблицу my_points колонку с именем point и типом geometry(Point,4326). Последний аргумент процедуры, число 2, задает размерность пространства. Число 4326 — это Spatial Reference System Identifier, или SRID. Потребность в SRID возникает по той причине, что существует множество способов представить координаты на поверхности земного шара. Очень часто используется SRID 4326, так как он соответствует системе координат WGS84, используемой в GPS.
Обратите внимание, что помимо типа geometry PostGIS также поддерживает тип geography. Отличие между ними заключается в том, что geography всегда хранится в WGS84, а также использует более дорогие, но и более точные, вычисления. Соответственно, geometry более гибок и быстр, но сравнительно менее точен. Более подробное обсуждение вопроса о том, что лучше использовать, можно найти здесь. В рамках этой заметки я буду использовать geometry, так как этот тип был выбран за меня утилитой osm2pgsql (см далее), а также потому что оба типа все равно легко преобразуются друг в друга.
Для преобразования строки к типу geometry используется процедура ST_GeomFromEWKT. EWKT означает Extended Well-Known Text. Это просто название формата, которому должно соответствовать текстовое представление геоданных в PostgreSQL.
Важно! Обычно в GPS-координатах сначала указывается широта (latitude), а затем долгота (longitude). Однако в EWKT все с точностью до наоборот, что часто приводит к ошибкам. Если для вас это является существенной проблемой, ее можно замести под коврик, написав несколько хранимых процедур на PL/pgSQL.
Посмотрим, что же записалось в таблицу:
-[ RECORD 1 ]---------------------------------------------
id | 1
name | Центр Москвы
point | 0101000020E6100000F2ED5D83BEE04B40B7EEE6A90ECF4240
То же самое, но более читаемо:
-[ RECORD 1 ]---------------------
id | 1
name | Центр Москвы
point | POINT(37.617635 55.755814)
И оно же, но в виде EWKT:
-[ RECORD 1 ]-------------------------------
id | 1
name | Центр Москвы
point | SRID=4326;POINT(37.617635 55.755814)
Кстати, приведенные координаты 55.755814, 37.617635 — это нулевой километр Москвы, а не Кремль или геометрический центр, как можно было бы ожидать.
Импорт данных из OpenStreetMap
Теперь нам нужны какие-то геоданные, и желательно побольше. Пожалуй, лучшим открытым источником геоданных является OpenStreetMap. Для наших страшных экспериментов качать весь OpenStreetMap не потребуется, вполне хватит европейской части России:
'russia-european-part-150101.osm.pbf'
Для импорта данных в PostgreSQL воспользуемся утилитой osm2pgsql:
./russia-european-part-150101.osm.pbf
Описание параметров можно прочитать в osm2pgsql --help. На моем ноутбуке импорт суммарно занял около двух часов, база заняла на диске 17 Гб. При этом нужно учесть, что PostgreSQL я никак не тюнил, а osm2pgsql использует его в процессе работы для хранения временных данных.
По завершении импорта мы увидим такие таблицы:
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------+----------
public | geography_columns | view | postgres
public | geometry_columns | view | postgres
public | planet_osm_line | table | eax
public | planet_osm_nodes | table | eax
public | planet_osm_point | table | eax
public | planet_osm_polygon | table | eax
public | planet_osm_rels | table | eax
public | planet_osm_roads | table | eax
public | planet_osm_ways | table | eax
public | raster_columns | view | postgres
public | raster_overviews | view | postgres
public | spatial_ref_sys | table | postgres
(12 rows)
Для нас наибольший интерес представляют таблицы planet_osm_point (различные точки — кафе, заправки, банки, аптеки, и так далее), planet_osm_roads (дороги), planet_osm_line (дороги вместе с прочими ломаными линиями), а также planet_osm_polygon (многоугольники, например, города). С этими данными можно работать на старом-добром SQL. Например, запрос:
FROM planet_osm_point
WHERE amenity <> ''
GROUP BY amenity
ORDER BY cnt DESC
LIMIT 10;
Вернет:
------------------+------
cafe | 9124
pharmacy | 8652
fuel | 7592
bank | 7515
waste_disposal | 7041
atm | 6487
bench | 6374
parking | 6277
restaurant | 5092
place_of_worship | 3629
(10 rows)
Как видите, в базе данных довольно много кофеен.
Если же данные хочется представить в графическом виде, можно воспользоваться программой QGIS:
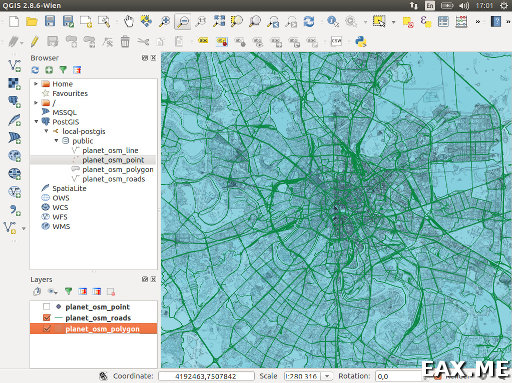
Вы просто добавляете слои, выставляете им прозрачность, шрифты, и прочие свойства по вкусу, а что выводить или не выводить определяете при помощи where-условия, которое можно указать в Layer → Query.
База кафе и городов
Перейдем, наконец, к работе с какими-то действительно полезными данными. Например, создадим таблицу, содержащую координаты кафе:
SELECT AddGeometryColumn('cafes', 'point', 4326, 'POINT', 2);
-- сразу создаем индекс
CREATE INDEX cafes_idx ON cafes USING gist(point);
-- заполняем данными из OSM
INSERT INTO cafes (name, point)
SELECT name, ST_Transform(way, 4326)
FROM planet_osm_point
WHERE amenity = 'cafe' AND name <> '';
Получилось 7099 кафе. Используемая здесь процедура ST_Transform преобразует координаты точки в заданную систему координат. Дело в том, что мы решили использовать SRID 4326, а в базе данных OSM используется SRID 900913.
В качестве индекса, как можно заметить, используется GiST. Тема того, как именно осуществляется поиск по геоданным, к сожалению, выходит за рамки сего поста. Если вас сильно интересует этот вопрос, рекомендую начать со статьи в Википедии, посвященной структуре данных R-Tree, а также статьи о GiST за авторством Егора Рогова на ХабраХабре.
По аналогии с кафе создаем таблицу с городами:
SELECT AddGeometryColumn('cities', 'polygon', 4326, 'POLYGON', 2);
CREATE INDEX cities_idx ON cities USING gist(polygon);
INSERT INTO cities(name, polygon)
SELECT DISTINCT ON (name) name, ST_Transform(way, 4326)
FROM planet_osm_polygon WHERE place = 'city';
Городов получилось 88. Часть запроса про DISTINCT ON (name) нужна из-за того, что некоторые города в базе OSM почему-то повторяются. Поэтому здес мы отбрасываем все координаты, кроме первых попавшихся.
На случай, если вам не хочется тратить время на импорт данных из OpenStreetMap, дампы таблиц cafes и cities были выложены мной на GitHub.
Примеры запросов
Допустим, мы находимся в центре Москвы. Попробуем найти ближайшие кофейни (способом, далеким от оптимального, см далее):
ORDER BY ST_Distance(
point,
ST_GeomFromEWKT('SRID=4326;POINT(37.617635 55.755814)')
)
LIMIT 3;
Результат:
name | Bosco cafe
st_asewkt | SRID=4326;POINT(37.6202483514509 55.754841394666)
-[ RECORD 2 ]-------------------------------------------------
name | Сбарро
st_asewkt | SRID=4326;POINT(37.6148290848364 55.7554166648134)
-[ RECORD 3 ]-------------------------------------------------
name | Krispy Kreme
st_asewkt | SRID=4326;POINT(37.6207745845443 55.7559774692132)
По Яндекс.Картам можно проверить, что эти кофейни действительно находятся в нескольких шагах от нулевого километра. Кстати, давайте посмотрим на точное расстояние:
ST_DistanceSphere(
point,
ST_GeomFromEWKT('SRID=4326;POINT(37.617635 55.755814)')
) AS dist
FROM cafes ORDER BY dist LIMIT 3;
Результат:
name | Сбарро
st_asewkt | SRID=4326;POINT(37.6148290848364 55.7554166648134)
dist | 181.04580332
-[ RECORD 2 ]-------------------------------------------------
name | Bosco cafe
st_asewkt | SRID=4326;POINT(37.6202483514509 55.754841394666)
dist | 196.05189625
-[ RECORD 3 ]-------------------------------------------------
name | Krispy Kreme
st_asewkt | SRID=4326;POINT(37.6207745845443 55.7559774692132)
dist | 197.28822555
Заметьте, что вместо ST_Distance, возвращающего расстояние в градусах, здесь мы используем ST_DistanceSphere, который возвращает расстояние в метрах, вычисленное на сфере (для более точных и дорогих расчетов на сфероиде есть ST_DistanceSpheroid). Того же эффекта можно добиться и с ST_Distance, если перобразовать ее аргументы в тип geography. В этом случае будет вызвана перегруженная версия процедуры, которая вернет расстояние в метрах:
ST_Distance(
point :: geography,
ST_GeomFromEWKT(
'SRID=4326;POINT(37.617635 55.755814)'
) :: geography
) AS dist
FROM cafes ORDER BY dist LIMIT 3;
Интересно, что если вы посмотрите в explain или expalin analyze приведенных выше запросов, то обнаружите там sequence scan. Так происходит по той причине, что ST_Distance и ST_DistanceSphere тупо берут и вычисляют расстояние между точками, просто не умея использовать какие-либо индексы. На нашем количестве точек это не так страшно, ведь запросы все равно выполняются за несколько миллисекунд. Но на большем количестве точек это может оказаться проблемой. Интересно, как же можно оптимизировать запрос?
Первое, что приходит на ум (и здесь это не лучшее решение, см далее) — отсечь заведомо слишком далекие точки. Беглое гугление показывает, что для этого есть готовая процедура ST_DWithin. Давайте попробуем:
FROM cafes
WHERE ST_DWithin(
point,
ST_GeomFromEWKT('SRID=4326;POINT(37.617635 55.755814)'),
0.005);
Как можно увидеть по explain запроса, теперь он выполняется с использованием индекса:
Index Cond: (point && '0103000020E6100000010000000500000046B1DCD26...
Filter: (('0101000020E6100000B7EEE6A90ECF4240F2ED5D83BEE04B40'::ge...
На моем ноутбуке запрос выполняется за 1.4 мс против 37 мс оригинального запроса, в 26 раз быстрее! К сожалению, поскольку данные мы храним в типе geometry, здесь мы можем указать лимит на расстояние лишь в градусах, но никак не в метрах. Преобразовать аргументы ST_DWithin к типу geography, чтобы работать с метрами, здесь не представляется возможным, так как это будут не те данные, по которым построен индекс. Можно примерно перевести градусы в метры из рассчета, что в одном градусе 60 морских миль, а в одной морской миле 1852 метра. Другими словами, в приведенном запросе мы ищем кафейни в радиусе около 500 метров. Для большей точности расстояние можно перепроверить при помощи того же ST_DistanceSphere.
Прием с ST_DWithin хорошо подходит в случаях, когда нужно найти все точки в некотором радиусе от заданной и, возможно, удовлетворяющие каким-то дополнительным критериям. Но иногда вместо поиска в определенном радиусе нужно найти N ближайших точек. Это совершенно другая задача, так как тот факт, что ближайшая точка может находится в 10 000 км, не имеет значения. Задача называется задачей поиска k ближайших соседей, она же k nearest neighbor, или просто kNN.
Для эффективного поиска ближайших соседей можно воспользоваться оператором <->:
name,
ST_AsText(point) AS gps,
ST_DistanceSphere(
point,
ST_GeomFromEWKT('SRID=4326;POINT(37.617635 55.755814)')
) AS dist
FROM cafes
ORDER BY point <-> ST_GeomFromEWKT(
'SRID=4326;POINT(37.617635 55.755814)'
)
LIMIT 10;
Результат:
---------------+------------------------------------------+-----------
Bosco cafe | POINT(37.6202483514509 55.754841394666) | 196.051896
Сбарро | POINT(37.6148290848364 55.7554166648134) | 181.045803
Krispy Kreme | POINT(37.6207745845443 55.7559774692132) | 197.288225
Прайм | POINT(37.6215543222109 55.7563930881115) | 253.550027
Кофемания | POINT(37.6216426266033 55.7548255720895) | 273.795992
Кофе Хауз | POINT(37.6220866638483 55.7570642764895) | 311.311280
Фестивальное | POINT(37.6227173710093 55.7545820653663) | 346.266479
Хлеб Насущный | POINT(37.614804381166 55.7602901970564) | 528.302044
Cinnabon | POINT(37.6147687180493 55.7604635130424) | 547.224001
Старбакс | POINT(37.6141981980123 55.7600708847645) | 519.899300
В этом запросе используется индекс. Однако, как можно видеть по колонке dist, результат получается не очень точным. Для PostgreSQL 9.4 и младше оператор <-> может оценить расстояние только примерно по центрам ограничивающих прямоугольников GiST-индекса. Для PostgreSQL 9.5 и старше оператор осуществляет «true kNN distance search», но есть нюансы. Для типа geometry, как в нашем случае, будет тупо посчитано расстояние в градусах. При этом меньшее расстояние в градусах совсем не обязательно означает меньшее расстояние в километрах! Для типа же geography расстояние вычисляется на сфере, а не на сферодие, используемом в WGS84.
Короче говоря, так называемый «true kNN distance search» все равно врет. Для решения этой проблемы нужно брать limit побольше и сортировать данные повторно. Например, так:
SELECT name, ST_AsText(point) AS gps,
ST_DistanceSphere(
point,
ST_GeomFromEWKT('SRID=4326;POINT(37.617635 55.755814)')
) AS dist
FROM cafes
ORDER BY point <-> ST_GeomFromEWKT(
'SRID=4326;POINT(37.617635 55.755814)'
)
LIMIT 15
) SELECT * FROM subq ORDER BY dist LIMIT 10;
Результат:
---------------+------------------------------------------+-----------
Сбарро | POINT(37.6148290848364 55.7554166648134) | 181.045803
Bosco cafe | POINT(37.6202483514509 55.754841394666) | 196.051896
Krispy Kreme | POINT(37.6207745845443 55.7559774692132) | 197.288225
Прайм | POINT(37.6215543222109 55.7563930881115) | 253.550027
Кофемания | POINT(37.6216426266033 55.7548255720895) | 273.795992
Кофе Хауз | POINT(37.6220866638483 55.7570642764895) | 311.311280
Фестивальное | POINT(37.6227173710093 55.7545820653663) | 346.266479
Хлеб Насущный | POINT(37.6229434769663 55.7573533115776) | 373.662496
Старбакс | POINT(37.6141981980123 55.7600708847645) | 519.899300
Хлеб Насущный | POINT(37.614804381166 55.7602901970564) | 528.302044
Вот теперь похоже на правду!
Теперь допустим, что мы стоим в центре Москвы, и хотели бы знать, в каком городе мы сейчас находимся :) Запрос:
FROM cities
WHERE ST_Within(
ST_GeomFromEWKT('SRID=4326;POINT(37.617635 55.755814)'),
polygon);
Результат предсказуем и для его получения использовался индекс. Очень хорошо. Интересно, а сколько кофеен в Москве?
Запрос:
LEFT JOIN cities AS cit ON cit.name = 'Москва'
WHERE ST_Within(caf.point, cit.polygon);
Оказывается, 1076. Ого, немало! Интересно, а сколько в других городах?
Запрос:
FROM cafes AS caf
INNER JOIN cities AS cit ON ST_Within(caf.point, cit.polygon)
GROUP BY cit.name
ORDER BY cnt DESC
LIMIT 10;
Результат:
-----------------+------
Москва | 1076
Санкт-Петербург | 979
Сочи | 222
Архангельск | 189
Владимир | 137
Краснодар | 134
Курск | 124
Воронеж | 124
Ставрополь | 91
Мурманск | 79
Как видите, все довольно просто!
Заключение
Эта статья не претендует на звание полного справочника по PostGIS. Выше были продемонстрированы лишь некоторые практические примеры его использования. При этом многие вопросы остались за кадром, в частности, вычисление площади полигонов (ST_Area), поиск всевозможных пересечений (ST_Intersection, ST_Union, ST_Difference, а также предикаты ST_Intersects, ST_Disjoint и подобные), работа с ломаными линиями, и так далее. Впрочем, со всеми этими вопросами теперь вы без труда разберетесь и самостоятельно. В качестве источников дополнительной информации я бы рекомендовал книги PostGIS Essentials и PostGIS in Action, Second Edition.
Дополнение: Также вас могут заинтересовать статьи Хранение и обработка временных рядов в TimescaleDB и Практический пример использования pgvector.
Метки: PostgreSQL, СУБД.
Вы можете прислать свой комментарий мне на почту, или воспользоваться комментариями в Telegram-группе.