Мини заметки – выпуск 5
Основные темы пятого выпуска: FreeBSD, Haskell, парное программирование, алгоритм шифрования lameCrypt на Perl и отрывки кода на PHP, имеющие отношение к поисковой оптимизации. Предыдущие выпуски: первый, второй, третий и четвертый.
1. Один интересный прием на Haskell
Этот отрывок кода я подглядел в архиве почтовой рассылки haskell-cafe:
{-# LANGUAGE FlexibleInstances, UndecidableInstances,
ScopedTypeVariables, OverlappingInstances #-}
import System.Random
class (Bounded a, Enum a) => BoundedEnum a
instance (Bounded a, Enum a) => BoundedEnum a
instance BoundedEnum a => Random a where
random gen = randomR (minBound :: a, maxBound :: a) gen
randomR (f, t) gen =
(toEnum r :: a, nextGen)
where
(rnd, nextGen) = next gen
r = fromEnum f + (rnd `mod` length [f..t])
Он позволяет говорить...
r <- randomIO :: Anything
...для любого типа Anything, являющегося экземпляром классов Enum и Bounded. Это позволяет не писать множество функций genRandomTypeN для каждого типа TypeN. В некоторых программах такой прием может быть очень полезен.
2. Удаленное парное программирование в screen
Есть несколько способов организовать удаленное парное программирование. Можно использовать для этого VNC или вашу IDE (такая возможность точно есть в Visual Studio, а также существует несколько плагинов для Eclipse). Но если вы и ваши коллеги предпочитают использовать VIM, то для удаленного парного программирования вы можете использовать утилиту screen.
Допустим, программисты с никами afiskon и eax решили программировать в паре с использованием screen. Для этого afiskon заходит на unix-сервер, где также имеет учетную запись eax, и говорит:
screen -R pairprog
:multiuser on
:acladd eax
Затем eax заходит на тот же сервер и выполняет команду:
screen -x afiskon/pairprog
Вот и все! См также man screen, особенно его часть про управление доступом (команда aclchg).
3. Оптимизация сайта под запросы с опечатками
Эту идею я подглядел на Blogerator.ru (см конец статьи). Идея состоит в том, чтобы находить в статье словосочетания на латинице и дописывать в конце эти словосочетания, набранные в русской раскладке. Например, если в статье встречаются слова «perl», «freebsd» и «haskell», то в конце статьи должно быть написано «зукд», «акууиыв» и «рфылудд». Это дело несложно автоматизировать:
// находим все словосочетания на английском
$content = preg_replace('/<[^>]+?>/', '', get_the_content());
preg_match_all('/\s+([a-z][a-z_\-\ ]{3,}[a-z])\s+/i',
$content, $match);
// приводим их к нижнему регистру и удаляем повторы
$keywords = array_map("strtolower", $match[1]);
$keywords = array_slice(array_unique($keywords), 0, 10);
// получаем опечатки
$replaceFrom = "abcdefghijklmnopqrstuvwxyz";
$replaceTo = mb_convert_encoding("фисвуапршолдьтщзйкыегмцчня",
"CP-1251", "UTF-8");
$funcCode =
'return mb_convert_encoding('.
'strtr($x, "'.$replaceFrom.'", "'.$replaceTo.'"), '.
'"UTF-8", "CP-1251");';
$rusKeywords = array_map(create_function('$x',$funcCode), $keywords);
// объединяем
$keywords = implode(", ", array_merge($keywords, $rusKeywords));
Я проверял, трафик с поисковых систем действительно увеличивается. Однако следует отметить, что Яндекс обещал жестоко наказывать за переоптимизацию сайтов, так что подумайте перед тем, как пользоваться это «темой».
4. BlogSpot + ZoneEdit
Если вы хотите создать сайт, но деньги есть только на доменное имя (от 100 рублей в год), воспользуйтесь следующей последовательностью шагов:
- Создаем блог на blogspot.com;
- Регистрируемся на zoneedit.com;
- Регистрируем доменное имя;
- Присваиваем доменному имени DNS'ы от ZoneEdit (например, ns5.zoneedit.com и ns7.zoneedit.com);
- Через ZoneEdit ставим в соответствие домену IP-адреса блогспота (на данный момент это 216.239.38.21, 216.239.32.21, 216.239.34.21 и 216.239.36.21);
- Проверяем настройки с помощью whois и dig (помним, что на обновление зоны нужны сутки);
- Если все ОК, прописываем в свойствах блога доменное имя;
- Получили бесплатный хостинг и бесплатные DNS сервера. Оплате подлежит только продление домена раз в год;
О том, как заработать на таком сайте, вы можете узнать из заметки Схема заработка в GoGetLinks, которая работает. Из недостатков приема – (1) зависимость от BlogSpot и ZoneEdit, (2) о добавлении сайта в SAPE придется забыть.
5. OpenDNS и GoogleDNS
OpenDNS:
nameserver 208.67.222.222
nameserver 208.67.220.220
GoogleDNS:
nameserver 8.8.8.8
nameserver 8.8.4.4
Запомнить наизусть!
6. Определение объема свободной памяти во FreeBSD
Во FreeBSD для определения суммарного объема свободной оперативной памяти с помощью, скажем, утилиты top требуется произвести дополнительные вычисления в уме. Я лично все время забываю, что с чем нужно складывать, поэтому предпочитаю использовать утилиту freecolor (легко ставится из пакеджей или портов).
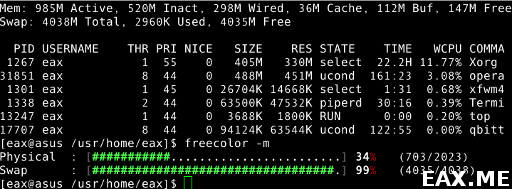
На приведенном скриншоте freecolor говорит, что 34% оперативной памяти (703 Мб) свободно. Все просто и понятно.
7. Проверка IP на наличие в спам-списках
Перепост отсюда:
www.spamhaus.org/query/bl?ip=1.1.1.1
www.senderbase.org/senderbase_queries/detailip?search_string=1.1.1.1
support.clean-mx.de/clean-mx/publog?ip=1.1.1.1
www.spamcop.net/w3m?action=checkblock&ip=1.1.1.1
Еще больше таких сервисов можно найти здесь.
8. Как не нужно шифровать данные
Некоторые задачи требуют быстрого решения. Если у вас нет времени на установку CPAN-модуля Crypt::Rijndael (код требуется развернуть на сотне серверов, нужен таск на админов, ...), можете воспользоваться алгоритмом вроде этого:
#!/usr/bin/env perl
use strict;
use Digest::MD5 qw/md5_hex/;
#use String::CRC32 qw/crc32/;
#sub md5_hex { sprintf("%08x", crc32(@_)) }
sub lameCrypt {
my ($str, $key, $decrypt) = @_;
return '' unless length($str);
unless($decrypt) {
my $iv = '';
while(length($iv) < 16) {
my $t; $t .= rand() for(0..7);
$iv .= md5_hex($iv.time().$$.$t);
}
$str = substr($iv, 0, 16).unpack("h*", $str);
}
my $l_len = int(length($str)/2);
my $r_len = length($str) - $l_len;
my $splitRe = qr/^(.{$l_len})(.{$r_len})$/o;
my ($rounds, $left, $right) = (32, undef, undef);
for my $i(1..$rounds) {
($left, $right) = $str =~ $splitRe;
my $f = '';
while(length($f) < $r_len) {
$f .= md5_hex(
$f.$left.($decrypt ? $rounds - $i + 1 : $i).$key
);
}
my $j = 0;
$right = join '', map {
sprintf("%x", hex($_)^hex(substr($f, $j++, 1)))
} split(//, $right);
$str = $right.$left;
}
$str = $left.$right;
return $str unless($decrypt);
return pack("h*", substr($str, 16, length($str)-16));
}
my $str = "secret message";
my $key = "aaa123";
my $enc = lameCrypt($str, $key, 0);
my $dec = lameCrypt($enc, $key, 1);
print "str = $str\nenc = $enc\ndec = $dec\n";
Алгоритм представляет собой сеть Фейстеля, причем размер блока равен длине (де)шефруемой строки. Если в строке нечетное количество байт, то при разбиении блока левая половина делается на один байт меньше правой. Функция F основана на алгоритме MD5.
Приведенный способ будет понадежнее какого-нибудь шифрования с помощью XOR, но он все равно ненадежен. Используйте приведенный код только в экстренном случае и только в качестве временного решения. Перед использованием обязательно внесите в алгоритм пару изменений (используемая хэш-функция, число итераций и тп).
9. FreeBSD – установка модулей Python из PyPI
Для установки модулей Python под FreeBSD оказалось очень удобно использовать утилиту pip.
pkg_add -r py27-pip # устанавливаем pip
pip search wordpress # поиск модулей
pip install pil # установка модуля
pip uninstall pil # удаление модуля
pip freeze # список установленных модулей
См также http://pypi.python.org/pypi.
10. Статистика поисковых запросов своими руками
В каком-нибудь footer.php дописываем:
<?php
$ref = $_SERVER['HTTP_REFERER'];
if(preg_match('/^http:\/\/(www\.)?(yandex|google)/', $ref)) {
$fid = fopen("/path/to/ref.txt", "a");
fwrite($fid, date("Y-m-d")."\t".$_SERVER['REQUEST_URI']."\t$ref\n");
fclose($fid);
}
?>
Ждем пару недель, после чего скармливаем файл ref.txt следующему скрипту:
#!/usr/bin/perl
# ref.txt parser v 0.1
# (c) Alexandr Alexeev 2012 | http://eax.me/
use strict;
use warnings;
use utf8;
use URI::Escape;
my $gre= qr"www\.google\.[^/]+/.*?[\#\?\&]{1}(?:as_)?q=([^\&]*)"i;
my $yre= qr"yandex\.[^/]+/.*?[\?\&]{1}(?:text|query)=([^\&]*)"i;
my $ire= qr"www\.google\.[^/]+/(notebook|reader|imgres|webhp)"i;
my %stat; # {url \t query} = cnt
my $fails = 0;
while(my $line = <>) {
chomp($line);
my($date, $url, $ref) = split /\t/, $line;
my $query;
if($ref =~ $gre) {
$query = $1;
} elsif($ref =~ $yre) {
$query = $1;
} else {
next if($ref =~ m"^http://[^/]+/?$"i);
next if($ref =~ m"www\.google\.[^/]+/search$"i);
next if($ref =~ m"doubleclick\.net/pagead/"i);
next if($ref =~ $ire);
warn "Failed to parse: $ref\n";
$fails++;
}
next unless($query);
$query = uri_unescape($query);
$query =~ s/\+/ /g;
$query =~ s/\s+/ /g;
$query = lc($query);
$stat{"$url\t$query"}++;
}
if($fails) {
warn "Total fails: $fails\n-----------\n";
}
for my $url_query(sort { $stat{$b} <=> $stat{$a} } keys %stat){
my($url, $query) = split /\t/, $url_query;
my $cnt = $stat{$url_query};
printf "%09d\t%s\t%s\n", $cnt, $url, $query;
}
Затем можно прогнать полученный список запросов через wordstat.yandex.ru и закупить внешних ссылок или провести внутреннюю оптимизацию сайта (перелинковка, заголовки и тп).
Собственно, это все. Как обычно, я буду несказанно рад вашим комментариям и вопросам.
Дополнение: Мини заметки – выпуск 6