Функциональщик ботает Java – работа со сторонними библиотеками и хождение в РСУБД
Итак, мы с вами настроили окружение для программирования на Java. Давайте же теперь попробуем что ли написать на ней какую-нибудь несложную программку, посерьезнее, чем Hello World. Например, программу, которая ходит в реляционную базу данных, выполняет какие-то запросы и получает результат.
Но сначала нам предстоит немного донастроить нашу IDE, в качестве которой, напоминаю, была выбрана IntelliJ IDEA. Идем в меню File → Settings → Editor и выбираем там галочку «Change font size (Zoom) with Ctr+Mouse Wheel». Это позволит менять размер шрифта в редакторе кода путем вращения колесика мыши при нажатом Ctr. Отрегулируйте размер шрифта в редакторе по своему вкусу и своим диоптриям.
Там же, в настройках, находим пункт Compiler. Ставим галочки Make project automatically и Compile independent modules in parallel. На наших, пока что небольших, проектах, параллельная фоновая компиляция не даст особого выигрыша, но в будущем это пригодится.
Как и положено нормальным программистам, код нового проекта мы будем держать в репозитории. Сходите на GitHub, BitBucket или чем вы там пользуетесь и заведите новый репозиторий. Лично я предпочитаю Git, но вы можете также выбрать Mercurial, Subversion или CVS. IntelliJ IDEA поддерживает их все. Клонируем куда-нибудь пустой репозиторий. Также можно воспользоваться готовым репозиторием. Например, у меня есть закрытый репозиторий на BitBucket, где я храню всякие поделки. Свой проект я разместил в подкаталоге этого репозитория.
Создадим новый проект. Как это делать, мы разобрались в предыдущем посте. В качестве groupId указываем ну например me.eax.examples, в качестве artifactId – JDBCExample, выбираем JDK 1.7, в качестве пути указываем путь к созданному ранее репозиторию или подкаталогу в уже существующем репозитории.
Дополнение: Тут я немного накосячил в плане принятых соглашениями о выборе groupId и artifactId. В последнем не принято использовать заглавные буквы. Подробнее об этом можно прочитать здесь.
Далее говорим VCS → Enable Version Control Integration. Если теперь в нижней панели открыть окно Changes, можно заметить, что IDE предлагает закоммитить много ненужных файлов. Похоже, нам понадобится .gitignore. Хороший файл .gitignore был нагуглен тут. Создаем в проекте новый файл с именем .gitignore, на вопрос «добавить ли его в репозиторий?» отвечаем «да», затем пишем:
# Eclipse
.classpath
.project
.settings/
# Intellij
.idea/
*.iml
*.iws
# Mac
.DS_Store
# Maven
log/
target/
Как и в прошлый раз, создаем пакет, заводим в нем новый класс, добавляем все файлы в репозиторий. В результате должна получиться такая картинка:
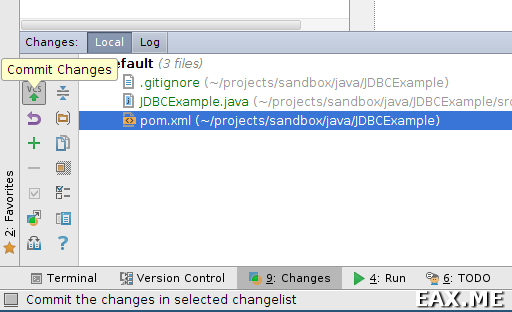
Все файлы должны быть зеленые. Нажимаем кнопочку Commit Changes (Ctr+K). Отмечаем галочкой все файлы, вводим Commit Message (ого, спелчекинг!), жмем Commit → Commit and Push. Надо отметить, интеграция с системами контроля версий в IntelliJ IDEA просто отличная. Например, если нажать на вкладку Log (см скриншот), то можно увидеть очень красивый граф коммитов и прочую информацию. Есть удобный просмоторщик diff'ов и так далее. Советую изучить окно Changes повнимательнее, там много интересного.
Теперь мы готовы к написанию программы. В качестве СУБД воспользуемся PostgreSQL. Хождение в базы данных в мире Java осуществляется через JDBC. Это такой обобщенный интерфейс, аналогичный DBI в мире Perl и HDBC или HDBI в Haskell. JDBC позволяет нам переключаться с одной РСУБД на другую без изменения кода приложения (конечно, если мы не завязались на какие-то специфические возможности некой РСУБД). Также, например, при появлении новой РСУБД разработчиком достаточно лишь написать драйвер для JDBC, и сразу все джавные ORM'ы и веб-фреймворки начнут работать с этой РСУБД.
JDBC драйвер для PostgreSQL не входит в JDK, нам придется каким-то образом самостоятельно прикрутить его к нашему приложению. Сторонние библиотеки в мире Java распространяются через репозитории – публичные в интернете или частные в локальной сети компании. Мы воспользуемся одним из общедоступных репозиториев.
Идем в File → Settings → Maven → Repositories, выбираем repo.maven.apache.org, жмем Update. Репозиторий большой, получение списка пакетов из него в первый раз займет довольно много времени. К счастью, во второй и последующие разы все будет намного быстрее. Да и производить такое вот обновление требуется не слишком часто. За процессом можно следить в статусбаре внизу IDE.
Открываем файл pom.xml, жмем Alt+Insert, выбираем Dependency, в строке поиска вводим «org.postgresql:postresql», ждем, когда обновится список, затем выбираем org.postgresql:postgresql:9.2-1004-jdbc4. На момент написания этих строк также был доступен пакет 9.3-1101-jdbc41, но у меня он что-то не заработал («SQLException: No suitable driver found»), то ли из-за не той версии JDBC, то ли потому что у меня локально работает PostgreSQL 9.2, не знаю. Справа вверху появится сообщение «Maven projects need to be imported». Нажимаем «Enable Auto-Import» и больше о нем не вспоминаем. В окне Project (Alt+1) в Exteral Libraries теперь можно увидеть импортированную библиотеку. Соответствующий jar'ник будет автоматически загружен в:
~/.m2/repository/org/postgresql/postgresql/9.2-1004-jdbc4
Примечание: Тут мы каким-то образом заранее узнали имя нужного пакета. Искать пакеты можно, например, через mvnrepository.com или search.maven.org. Если провести аналогию с Haskell и Perl, то это своего рода аналоги Hackage и CPAN.
Нам может захотеться изучить документацию (JavaDoc) к драйверу PostgreSQL и, возможно, его исходники. Получить и то и другое можно либо выполнив в терминале, который, кстати, открывается нажатием Alt+F12:
mvn dependency:sources
mvn dependency:resolve -Dclassifier=javadoc
... либо через окно Maven Projects, кнопку для открытия которого можно найти в правой панели. В File → Settings → Maven → Importing можно настроить IntelliJ IDEA так, чтобы она автоматически загружала исходники и/или документацию при добавлении новой зависимости (Automatically download).
Теперь вводим следующий код:
package me.eax.examples;
import java.sql.*;
public class JDBCExample {
static final String host = "jdbc:postgresql:test_database";
static final String user = "test_user";
static final String pass = "qwerty";
public static void main(String args[]) {
try (
Connection conn = DriverManager.getConnection(host, user, pass);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("select * from phonebook")
/* stmt.executeUpdate for insert, update or delete */
) {
while(rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
String phone = rs.getString("phone");
Date changed = rs.getDate("last_changed");
System.out.format("%d %s %s %s\n", id, name, phone, changed);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
При вводе кода IntelliJ IDEA может возмутиться – что-то по поводу настроек языка и переключения на использование Java 7. Если такое произойдет, соглашайтесь.
Здесь я использовал ту же базу данных, которую мы создали при написании телефонной книги на Haskell. Во время ввода кода IntelliJ IDEA будет заботливо предлагать автокомплит. Если отступы получатся немного неровными, привести код к одному code style можно нажатием Ctr+Alt+I. Кроме того, вы также можете посмотреть документацию к классам и их методам, поставив курсор на них и нажав Ctr+Q:
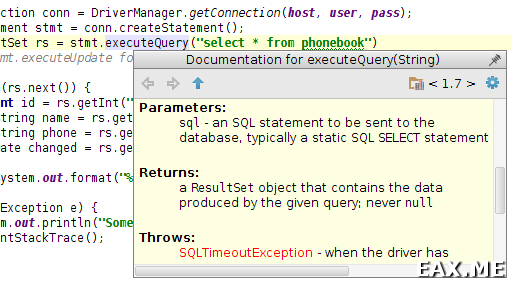
Кстати, обратите ваше внимание на использованную в коде конструкцию try with resources, появившуюся в Java 7. В случае возникновения любого исключения у объектов conn, stmt и rs будут автоматически вызваны методы close(). Раньше все это приходилось делать вручную, используя finally блок и проверяя, не равны ли переменные null. Должно быть, страшные были времена.
В старых туториалах можно прочитать что-то про необходимость написания Class.forName для того, чтобы подгрузить драйвер. Если вам попадется такой туториал, имейте в виду, что эта информация устарела и так делать давно не нужно.
Жмем Ctr+Shift+F10, проверяем, что программа работает. Например, у меня она вывела следующее:
1 Alex 123 2014-01-31
2 Bob 456 2014-01-31
Process finished with exit code 0
Похоже на правду.
Как и в прошлый раз, можно собрать jar'ник, используя maven-assembly-plugin (не забываем поменять mainClass!). Но если вы просто скажете:
mvn compile assembly:single
... то получите ошибку вроде:
error: try-with-resources is not supported in -source 1.3
Оказывается, по умолчанию Maven собирает проект, используя Java 1.3. А нам нужна Java 1.7. Эта проблема решается при помощи еще одного плагина. В pod.xml находим секцию plugins и дописываем:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
Собираем jar'ник, проверяем его работу, сказав java -jar – в этот раз все должно получиться. Джарник увеличился в размере, но не сказать, что очень сильно. У меня его размер составил всего лишь около 580 Кб. Не забываем все это хозяйство закоммитить.
Кстати, чтобы в каждом новом проекте не заводить файл .gitignore и не заполнять pod.xml, можно сделать все это один раз, а затем сказать Tools → Save Project as Template. При создании нового проекта можно будет выбрать шаблон в списке User-defined (вместо Java/Maven, который мы выбирали до сих пор).
Дополнение: Краткий обзор GUI-фреймворков для Java и мое первое простенькое GUI-приложение на Swing