Массовая проверка тИЦ на Perl
C недавних пор я стал увлекаться SEO. Порой передо мной встает задача быстро проверить индекс цитирования десятка-другого сайтов. Вот как я решаю эту проблему.
Вообще-то, можно не изобретать велосипед, и воспользоваться уже готовыми сервисами, например http://www.cy-pr.com/masscheck. Проблема тут в том, что они отображают тИЦ в виде картинки (url: http://yandex.ru/cycounter/?$SITE_NAME), а значит результат проверки не получится сохранить в текстовом файле или отсортировать в Excel OpenOffice.
Оказывается, Яндекс может выдавать тИЦ сайтов в текстовом виде по адресу http://search.yaca.yandex.ru/yca/cy/ch/$SITE_NAME. Уже не помню точно, как и когда я это выяснил. Учитывая вышесказанное, можно автоматизировать проверку тИЦ.
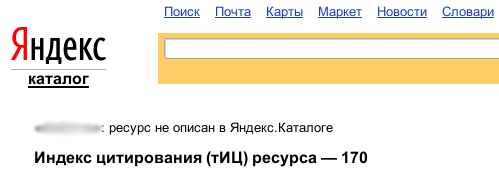
В зависимости от того, находится ли сайт в Яндекс.Каталоге, страница с его тИЦ будет выглядеть по-разному. Вариант первый – если сайта нет в каталоге.
Вариант второй – если сайт в каталоге:
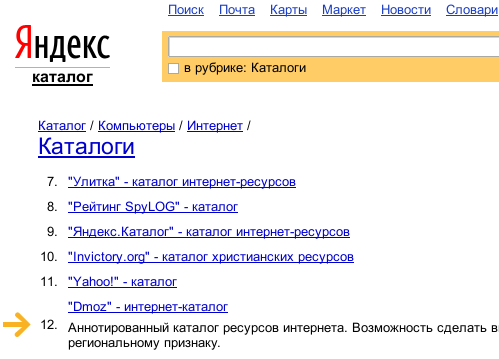
На скриншоте не видно, но напротив имен сайтов отображается их тИЦ. В первом случае интересующий нас html-код страницы выглядит так:
<table class="content" border="0" cellpadding="10" cellspacing="0" width="100%">
<tr>
<td class="body left">
<p>«*******»: ресурс не описан в Яндекс.Каталоге</p>
<p class="errmsg">
<b>Индекс цитирования (тИЦ) ресурса — 170</b>
</p>
</td>
</tr>
</table>
Во втором:
<tr valign="top">
<td class="current" valign="middle"><img border="0" height="25" ⏎
width="28" alt="" src="http://img.yandex.net/i/arr-hilite.gif"/></td>
<td align="right" valign="middle" width="20">12.</td>
<td width="*" valign="middle">
<a href="http://www.dmoz.org/">"Dmoz" - интернет-каталог</a>
<div>Аннотированный каталог ресурсов интернета. Возможность сделать ⏎
выборку ресурсов по региональному признаку. </div>
</td>
<td align="right">1900</td>
</tr>
Ну и теперь все, что нам остается, это немного пораскинуть мозгами, составляя регулярные выражения, и написать небольшой скрипт. У меня получилось следующее:
#!/usr/bin/perl
# cy-check.pl script
# (c) Alexandr Alexeev 2009 | http://eax.me/
use strict;
while(my $site = <stdin>) {
chomp($site);
# urlencode
$site =~ s/([^a-zA-Z0-9.\-]{1})/sprintf("%%%02x",ord($1))/eg;
my $url = "http://search.yaca.yandex.ru/yca/cy/ch/$site/";
my $data;
for (1..5) { # attempts
$data = `wget -q $url -O -`;
if(!$data or $?) {
die "$site: download failed\n" if ($_ == 5);
} else { last; }
}
my ($cy1) = $data =~ qr{<p class="errmsg">\n<b>\D+(\d+)</b>};
my ($cy2) = $data =~ qr{<td class="current".*<td align="right">(\d+)</td>}s;
printf "%09d:%s\n", $cy1 > $cy2 ? $cy1 : $cy2, $site;
}
Скрипт можно использовать в сочетании с sort и awk. Похоже, что в отличие от Google, Яндекс не пытается блокировать доступ к этой странице по IP или с помощью каких-то ключей. Но тем не менее, злоупотреблять скриптом я бы не советовал. Потому не предлагаю CGI-версию.
Кстати, я использую этот скрипт не только при покупке ссылок с сайтов, но и при выборе интернет-магазина. А как еще понять, какой магазин лучше, если не по тИЦ?
Дополнение: Немного изменив последние несколько строк, можно использовать скрипт для проверки наличия сайта в Яндекс.Каталоге.