Язык Rust, как типизированный и более быстрый Python
Исторически Rust позиционировался, как «убийца C++». Этим он с одной стороны привлек к себе внимание, а с другой – подвергся критике на предмет того, что убить C++ так просто не получится. Кое-какая старая критика языка по состоянию на сегодняшний день уже не актуальна. В частности, по Rust была написана куча книг. Имеется множество готовых библиотек и некоторое количество вакансий. Появились классные инструменты разработки, взять к примеру тот же Zed. К слову, последний написан на Rust.
В качестве примера актуальной критики можно привести в пример такую. В безопасном подмножестве Rust имеются ненужные накладные расходы. Не слишком большие, но и не нулевые. Так инициализация выделенной памяти происходит всегда. Чтобы код компилировался, иногда приходится прибегнуть либо к использованию Rc/Arc, либо дополнительному копированию данных. Под алгебраические типы данных выделяется больше памяти, чем нужно для хранения конкретного значения. В рантайме осуществляются проверки на выход за границы массивов. Имеются и другие примеры, но субъективно они не так значимы.
При необходимости программу можно оптимизировать, прибегнув к написанию unsafe{} кода. Но без острой необходимости unsafe{} стараются избегать. Это лишняя работа, которая приводит к менее читаемому коду. Кроме того, менее эффективная и корректно работающая программа обычно предпочтительнее более эффективной, но потенциально падающей на проде в два часа ночи.
Казалось бы, соревноваться в скорости с C/C++ при таких условиях непросто. Тем не менее, на сегодняшний день Rust является одним из немногих языков, который демонстрирует производительность уровня C/C++, и это достойно восхищения:
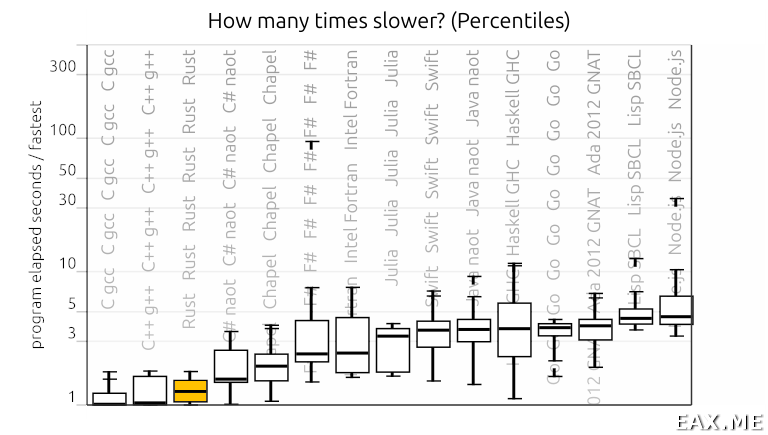
Есть мнение, что не надо соревноваться ни с какими C/C++. Тем более, не надо пытаться переписать весь существующий код с C/C++ на Rust. Rust – это просто нормальный язык со своими компромиссами, пригодный для многих практических задач. Если язык нравится и подходит для стоящих перед вами задач, то смело используйте. Не нравится и/или не подходит – не используйте.
Я, например, не считаю, что все существующие проекты на C/C++ нужно обязательно переписать на Rust. Однако я понимаю сделанные в Rust компромиссы. Имеется широкий класс задач, который я мог бы решать при помощи Rust. При этом не похоже, чтобы Rust в обозримом будущем мог внезапно исчезнуть. А значит, время, инвестированное в его изучение, вряд ли окажется потраченным впустую.
Почему существующие проекты не обязательно переписывать на Rust? Потому что зачастую практичнее создать совершенно новый проект на Rust, и учесть в нем все ошибки старого проекта, в том числе архитектурные. А старые проекты пусть себе спокойно живут в том виде, в каком они есть, и никому ничего не ломают.
Помимо прочего, меня интересует, насколько Rust применим в качестве «типизированного и более быстрого Python». Понятно, что с более высоким порогом вхождения, компиляцией под каждую конкретную платформу, без REPL, и так далее. Но тем не менее. (Вообще-то, уместнее было бы назвать Rust «переосмысленным и ускоренным OCaml». Но чтобы данное сравнение вызывало какие-то ассоциации, нужен опыт программирования на OCaml, коим в наши дни располагает не каждый.)
Считается, что Rust и Python предназначены для разных задач. Rust позиционируется, как язык системного программирования (для написания операционных систем, компиляторов, виртуальных машин, ...), тогда как Python является языком прикладного программирования (для написания бизнес-логики). Но ведь ничто не мешает применить Rust для решения тех задач, которые обычно решаются на Python. Давайте попробуем, и посмотрим, что из этого выйдет.
Эксперименты проводились на моем ноутбуке с Ubuntu 24.04. Для установки Rust говорим:
$ sudo apt install rustup
$ rustup update stable
В качестве первого примера напишем программу, считающую количество уникальных строк, полученных из stdin. Это не очень-то реалистичная программа. Однако она дает представление о работе со строками и множествами.
Версия на Python:
#!/usr/bin/env python3
import sys
unique_lines = set()
for line in sys.stdin:
unique_lines.add(line.rstrip())
print(f"Number of unique lines: {len(unique_lines)}")
А вот то же самое, но на Rust:
use std::collections::HashSet;
use std::io::{self, BufRead};
fn main() {
let stdin = io::stdin();
let mut unique_lines = HashSet::new();
for line in stdin.lock().lines() {
match line {
Ok(content) => unique_lines.insert(content),
Err(_) => break,
};
}
println!("Number of unique lines: {}", unique_lines.len());
}
Пока что код выглядит более-менее одинаково. Заметьте, что как set() в Python, так и HashSet в Rust, имеют счетчик количества элементов. Поэтому определение количества элементов по выходу из цикла выполняется за O(1) в обоих случаях.
Перейдем к чуть более интересному примеру. Вот скрипт, определяющий IP-адрес компьютера, на котором он запущен, при помощи сервиса 2ip.ru:
#!/usr/bin/env python3
import requests
headers = {'User-Agent': 'curl/8.5.0'}
response = requests.get('http://2ip.ru/', headers=headers)
print(response.text.strip())
... и его версия на Rust:
use ureq;
fn main() {
let get_result = ureq::get("http://2ip.ru/")
.set("User-Agent", "curl/8.5.0")
.call();
let response = match get_result {
Ok(response) => response,
Err(error) => {
println!("Error: Failed to make HTTP request: {}", error);
return;
}
};
match response.into_string() {
Ok(body) => println!("{}", body.trim()),
Err(error) => {
println!("Error: Failed to read response body: {}", error);
return;
}
};
}
HTTP-клиентов для Rust существует больше одного. Конкретно ureq был выбран произвольным образом. Это довольно тяжелый пакет со множеством зависимостей. Проверим, как быстро компилируется код:
$ cargo clean
$ time cargo build # dev-сборка
$ time cargo build -r # release-сборка
На моем ноутбуке dev-сборка занимает 4.5 секунды, а release-сборка – 7.5 секунд. Последняя занимает больше времени, потому что лучше оптимизирует код. Заметьте, что это время компиляции проекта с нуля. Когда вы правите отдельные файлы, сборка происходит инкрементально.
Часто скриптовые языки используют для парсинга всевозможных текстовых файлов, вроде логов Nginx. Рецепт усредненный:
#!/usr/bin/env python3
import sys
import re
log_re = re.compile(r'^(\S+) \S+ \S+ \[([^\]]+)\] "(\S+) (\S+) \S+" (\d+)')
html_requests = {}
for line in sys.stdin:
line = line.rstrip()
match = log_re.match(line)
if match:
method = match.group(3)
url = match.group(4)
status_code = int(match.group(5))
if method == 'GET' and url.endswith('.html') and status_code == 200:
if url in html_requests:
html_requests[url] += 1
else:
html_requests[url] = 1
pairs = list(html_requests.items())
pairs.sort(key=lambda x: x[1], reverse=True)
for url, count in pairs:
print(f"{count} {url}")
В переводе на Rust получаем:
use regex::Regex;
use std::collections::HashMap;
use std::io::{self, BufRead};
const RE: &str = r#"^(\S+) \S+ \S+ \[([^\]]+)\] "(\S+) (\S+) \S+" (\d+)"#;
fn main() {
let regex = Regex::new(RE).unwrap();
let mut html_requests = HashMap::new();
let stdin = io::stdin();
for line in stdin.lock().lines() {
let line = match line {
Ok(line) => line,
Err(_) => break,
};
let captures = match regex.captures(&line) {
Some(captures) => captures,
None => continue,
};
let method = &captures[3];
let url = &captures[4];
let status_code: u32 = captures[5].parse().unwrap_or(0);
if method == "GET" && url.ends_with(".html") && status_code == 200 {
match html_requests.get_mut(url) {
Some(count) => *count += 1,
None => {
html_requests.insert(url.to_string(), 1);
}
}
}
}
// collect() возвращает вектор кортежей (URL, счетчик)
let mut pairs: Vec<_> = html_requests.iter().collect();
pairs.sort_by(|(_, a), (_, b)| b.cmp(a));
for (url, count) in pairs {
println!("{} {}", count, url);
}
}
Проверим обе версии на логах этого сайта за декабрь:
$ time cat eaxme-2025-12.log | ./python/nginx_log_analyzer.py
$ time cat eaxme-2025-12.log | ./rust/target/release/nginx_log_analyzer
Исходный файл имеет размер 1.2 Гб и содержит 4.8 млн строк. Версия на Python справляется с задачей за 3 секунды, а версия на Rust... за 4.5 секунды. Вот тебе раз! Казалось бы, программы делают одно и то же, и Rust при прочих равных должен быть быстрее. Я пробовал собирать код на Rust с дополнительными флагами оптимизации, не исключая link-time optimization, но это не помогло.
Такое могло произойти по нескольким причинам. Вот наиболее вероятные. 1) Регулярные выражения в Python реализованы эффективнее крейта regex в Rust. 2) Реализация строк в Python быстрее реализации строк в Rust. Напомню, что Rust хранит строки в UTF-8, тогда как Python работает с символами фиксированного размера. 3) Python выигрывает, потому что откладывает сборку мусора на потом, а Rust выполняет ее сразу. 4) Автор не до конца разобрался и написал неэффективный код. Интересно, что по этому поводу скажут бывалые программисты на Rust.
Дополнение: Профилирование при помощи cargo flamegraph показало, что программа проводит ~70% времени в крейте regex, что говорит в пользу версии #1.
Подведем итоги. Можно ли использовать Rust в качестве замены Python?
При желании, можно. За скорость исполнения и строгую типизацию мы предсказуемо расплачиваемся увеличением количества кода, а также появлением какого-то времени компиляции. Объем кода увеличивается примерно в два раза. Примечательно, что читаемость при этом как будто бы не страдает. В рассмотренных примерах программы компилируются сравнительно быстро. Как с этим обстоят дела в крупных проектах, на данном этапе я судить не могу.
Следует помнить, что ускорение кода за счет преписывания с Python на Rust в общем случае не гарантируется. Может получиться, как в примере с регулярными выражениями. Это в очередной раз доказывает, что нужно не просто доверять чужим бенчмаркам, а проверять их на своих задачах, своем железе, а также своем уровне владения технологией.
Полную версию исходников к посту вы найдете в этом архиве. Ваши вопросы, возражения и комментарии, как всегда, горячо приветствуются.
Дополнение: Также вас могут заинтересовать посты Шпаргалка по многопоточности в языке Rust, Изучаем возможности Matrix SDK для Rust, и далее по ссылкам.