Мини заметки – выпуск 2
В эфире второй выпуск мини-заметок. В него вошли девять «недопостов», связанных с юниксами, сайтостроением, информационной безопасностью и написанием скриптов. Кажется, предыдущий выпуск вызвал у читателей исключительно положительные эмоции. Надеюсь, этот окажется не хуже.
1. Безвозвратное удаление файлов в UNIX
Не секрет, что при удалении файла с диска его содержимое на самом деле никуда не исчезает. Оно продолжает хранится где-то на диске. Другой вопрос, что мы точно не знаем, где именно. Если у нас был файл, и мы случайно его удалили, для его восстановления нужно просканировать весь диск. Если после удаления файла прошло мало времени и его содержимое не было затерто другими файлами, с большой вероятностью его удастся полностью восстановить.
На этом принципе основана работа множества программ для восстановления данных, таких, как Easy Recovery. Однако они не гарантируют 100% восстановления данных. Поэтому в мире UNIX такие программы не получили широкого распространения – здесь принято регулярно делать резервные копии. Тогда данные можно будет восстановить и в случае случайного удаления, и пожара, и землетрясения.
Иногда встает обратная задача – как удалить файл таким образом, чтобы его нельзя было восстановить? Например, если мы хотим избавится от письма с секретной информацией. Очевидное решение – сначала полностью переписать его, а только затем удалить. Однако даже в этом случае есть шанс восстановить файл по остаточным данным на жестком диске, поэтому перезапись производится многократно.
В UNIX есть специальная программа для безвозвратного удаления файлов под названием wipe. Во FreeBSD ее можно установить из портов – /usr/ports/security/wipe/. Ее основные аргументы:
-p(1-32) - число проходов
-x[1-32] - максимальное значение случайного числа проходов
Аргумент -x3 означает «присвоить x случайное значение от 1-го до 3-х». Общее число проходов вычисляется, как x * p. Примеры:
# три раза переписать файл и затем удалить его
wipe -p3 file1.txt
# затереть файл от 1 до 4 раз, затем удалить
wipe -p1 -x4 file2.txt
# безвозвратно удалить каталог и его содержимое
# (один проход перезаписи)
wipe -r /dir/
Теперь представим, что нам нужно полностью очистить целую флешку. Самый простой способ – полностью заполнить ее нулями:
dd if=/dev/zero of=/dev/da1 bs=1M
Более надежный способ – многократно затереть все данные на флешке:
for n in 1 2 3; do dd if=/dev/urandom of=/dev/da1 bs=1M; done;
После этого нужно создать новую файловую систему. Сначала говорим
fdisk -I /dev/da1
Утилита должна вывести что-то вроде:
******* Working on device /dev/da1 *******
fdisk: invalid fdisk partition table found
fdisk: Geom not found: "da1"
После этого в /dev должен появится da1s1
newfs_msdos /dev/da1s1
Монтируем, проверяем.
Сколько раз нужно перезаписывать данные? Судя по существующим стандартам, трех раз вполне достаточно. Если данные не шибко секретные, можно ограничится и одним разом.
Дополнение: Оказывается, на ZFS утилиты типа wipe не работают.
2. Прикручиваем к блогу OpenSearch
OpenSearch – этой такой API для поиска по сайту. Вот как это выглядит:
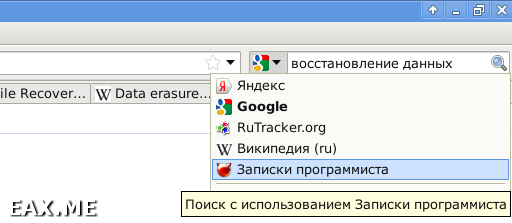
В блогах на WordPress ОпенСёрч добавляется так. Сначала в корне сайта создается файл osd.xml следующего содержания:
<?xml version="1.0" encoding="utf-8"?>
<OpenSearchDescription xmlns="http://a9.com/-/spec/opensearch/1.1/">
<ShortName>Записки программиста</ShortName>
<LongName>Записки программиста</LongName>
<Description>Поиск в блоге “Записки программиста”</Description>
<Url type="text/html" template="http://eax.me/?s={searchTerms}"/>
<Url type="application/atom+xml" template="http://eax.me/?⏎
feed=atom&s={searchTerms}"/>
<Url type="application/rss+xml" template="http://eax.me/?⏎
feed=rss2&s={searchTerms}"/>
<Image height="16" width="16" type="image/vnd.microsoft.icon">⏎
http://eax.me/favicon.ico</Image>
<Language>ru-RU</Language>
<OutputEncoding>UTF-8</OutputEncoding>
<InputEncoding>UTF-8</InputEncoding>
</OpenSearchDescription>
Надеюсь, что на что нужно заменить, понятно без объяснений? Затем прописываем в header.php нашей темы между <head> и </head> следующую строчку:
<link rel="search" type="application/opensearchdescription+xml" ⏎
href="http://eax.me/osd.xml" title="Записки программиста" />
Готово! В отличие от всяких плагинов для WordPress этот прием не палит e-mail администратора. Кроме того, описанным способом OpenSearch можно прикрутить к сайту на любой CMS.
3. Прикручиваем к доменному имени OpenID
Чтобы использовать доменное имя в качестве OpenID, совсем не обязательно иметь собственный OpenID сервер. Это возможно благодаря так называемому «делегированию OpenID». Допустим, мы зарегистрированы в Blogger и у нас есть сайт example.ru. Последний мы хотим использовать в качестве OpenID. Редактируем шаблон сайта, добавляя между <head> и </head> следующее:
<link rel="openid.server" href="http://draft.blogger.com/openid-server.g" />
<link rel="openid.delegate" href="http://afiskon.blogspot.com/" />
Или, если вы предпочитаете LiveJournal:
<link rel="openid.server" href="http://www.livejournal.com/openid/server.bml" />
<link rel="openid.delegate" href="http://afiskon.livejournal.com/" />
Разумеется, «afiskon» нужно заменить на свой ник. Теперь идем на какой-нибудь сайт и пытаемся войти под OpenID «example.ru». Если мы нигде не ошиблись, все должно работать.
4. Размножение статей на Perl
Тут, если позволите, без комментариев.
#!/usr/bin/perl
use strict;
# text-morph.pl | (c) Alexandr Alexeev 2010 | http://eax.me/
# можно напихать лишних пробелов
# а затем вырезать их s/\s+/ /g
my $text = "{Hi|{Hello|Good day}}, {world|people}!";
for(1..10) {
print text_morph($text)."\n";
}
sub text_morph {
my $text = $_[0];
my $save = "";
while($save ne $text) {
$save = $text;
$text =~ s/\{([^\{\}]+)\}/text_select($1)/eg;
}
return $text;
}
sub text_select {
my @text = split /\|/, $_[0];
return $text[rand(@text)];
}
5. Полезные SQL-запросы к БД форума на punBB
Как я познакомился с этим движком, можете прочитать в этом посте. Ниже приведены несколько запросов для определения различных характеристик форума на punBB.
Зачем это нужно? Допустим, отношение (постов на форуме)/(участников на форуме) упало в два раза за пол года. Это говорит о падении «лояльности» посетителей – люди регистрируются, пишут десяток постов, затем навсегда уходят. Форум загибается и с этим нужно что-то делать. Очень интересная серия статей в тему публиковалась на rxpblog.com – часть 1 и часть 2.
Определить количество новых постов за месяц:
SELECT YEAR(from_unixtime(posted)) AS y,
MONTH(from_unixtime(posted)) AS m,
count(id)
FROM punbb_posts
GROUP BY y, m
ORDER BY y, m;
Топиков создается в месяц:
SELECT YEAR(from_unixtime(posted)) AS y,
MONTH(from_unixtime(posted)) AS m,
count(id)
FROM punbb_topics
GROUP BY y, m
ORDER BY y, m;
Регистраций в месяц:
SELECT YEAR(from_unixtime(registered)) AS y,
MONTH(from_unixtime(registered)) AS m,
count(id)
FROM punbb_users
WHERE YEAR(from_unixtime(registered)) > 1970
GROUP BY y, m
ORDER BY y, m;
Число активных участников (создали не менее 30 постов за месяц):
SELECT y, m, count(DISTINCT username) AS c
FROM (
SELECT YEAR(from_unixtime(posted)) AS y,
MONTH(from_unixtime(posted)) AS m,
username,
count(p.id) AS cnt
FROM punbb_posts AS p
LEFT JOIN punbb_users AS u
ON p.poster_id = u.id
GROUP BY y, m, username
) AS t
WHERE cnt >= 30
GROUP BY y, m
Пересчитать количество постов у каждого пользователя:
UPDATE punbb_users AS u SET num_posts = (
SELECT count(*) FROM punbb_posts WHERE poster_id = u.id
)
Поиск потенциальных ботов (удалять лучше вручную!):
SELECT id, username, last_visit, num_posts
FROM punbb_users
WHERE TRUE
AND id > 1
AND (unix_timestamp(now()) - last_visit > 90*24*60*60)
AND num_posts = 0
ORDER BY id;
Во всех запросах «punbb_» нужно заменить на используемый вами префикс в именах таблиц.
6. Установка Perl-модулей без прав суперпользователя
Создаем каталог ~/perl-modules/ – здесь будут хранится установленные модули. Ставить будем с помощью утилиты cpan. Во время первого запуска утилита задаст нам ряд вопросов. На все следует ответить по умолчанию, кроме следующих:
...
Would you like me to configure as much as possible automatically? [yes] no
...
Always commit changes to config variables to disk? [no] yes
...
Please enter the URL of your CPAN mirror http://cpan.rinet.ru/
...
Parameters for the 'perl Makefile.PL' command? [INSTALLDIRS=site] PREFIX=~/perl-modules/
...
В ~/.bashrc дописываем:
export PERL5LIB=/home/eax/perl-modules/lib/perl5/site_perl/5.10.1
Перезаходим, ставим модули, проверяем их работу.
7. Удаляем не-mp3 файлы
Избавляемся от всяких .jpg, .m3u и прочего мусора в нашей аудио коллекции:
find './Infected Mushroom - Discography/' -type f | \
grep -v \\.mp3\$ | perl -e 'chomp $_ and unlink $_ while(<>);'
По аналогии можно делать много других полезных вещей.
8. Качаем порты FreeBSD по HTTP вместо FTP
Этот примем пригодится тем, кому по каким-то причинам не нравится использовать протокол FTP. Я лично против него ничего не имею, но из-за каких-то хитрых настроек фаервола моего ISP с ним постоянно возникают проблемы. При использовании протокола HTTP таких проблем нет, потому в моем /etc/make.conf написано следующее:
# замена утилите fetch
FETCH_CMD=/usr/local/bin/wget -T 3 -c
# не указываем флаг -S, wget понимает его не так, как fetch
DISABLE_SIZE=yes
# отдаем предпочтение протоколу HTTP
MASTER_SORT_REGEX=^http
# откуда льем исходники
MASTER_SITE_BACKUP?= \
http://ftp3.ru.freebsd.org/pub/FreeBSD/ports/distfiles/${DIST_SUBDIR}/\
http://ftp4.ru.freebsd.org/pub/FreeBSD/ports/distfiles/${DIST_SUBDIR}/\
http://ftp5.ru.freebsd.org/pub/FreeBSD/ports/distfiles/${DIST_SUBDIR}/\
http://ftp6.ru.freebsd.org/pub/FreeBSD/ports/distfiles/${DIST_SUBDIR}/\
http://ftp2.ru.freebsd.org/pub/FreeBSD/ports/distfiles/${DIST_SUBDIR}/\
http://ftp1.ru.freebsd.org/pub/FreeBSD/ports/distfiles/${DIST_SUBDIR}/
MASTER_SITE_OVERRIDE?= ${MASTER_SITE_BACKUP}
Если вы используете пакеджи, пропишите в /root/.cshrc
setenv PACKAGEROOT http://ftp3.ru.freebsd.org
Все готово. Теперь все исходники и пакеджи будут скачиваться с российских http-серверов утилитой wget.
9. Полезные утилиты
Здесь я хотел бы рассказать о нескольких полезных программах, которые можно найти в портах FreeBSD.
Утилита eject (/usr/ports/sysutils/eject) предназначается для открытия дисковода:
eject /dev/acd0
Программа tree (/usr/ports/sysutils/tree) рекурсивно обходит каталог и выводит его содержимое в виде дерева. Ограничить глубину рекурсии можно с помощью колюча -L.
tree -L 3 ~/
С помощью shuffle (/usr/ports/misc/shuffle) можно перемешивать строки текстового файла. Казалось бы, кому это нужно? Однако в моих скриптах такая необходимость возникает довольно часто.
# проигрываем mp3 файлы в случайном порядке
find ~/mp3 | shuffle -f - | mpg123 -@ -
Дополнение: Лучше использовать утилиту rl (/usr/ports/textproc/rl), потому что shuffle есть только под *bsd. В Linux утилита shuffle тоже есть, но предназначена для других целей. Пользоваться rl просто – cat file | rl | head.
Утилита enconv (/usr/ports/converters/enca) предназначена для перекодирования файлов из одной кодировки в другую. В отличие от iconv здесь исходная кодировка определяется автоматически. Если нам известно, с каким языком мы работаем, с помощью ключа -L его можно сообщить программе.
wget -q 'http://example.ru/' -O - | enconv -L none -x utf8 > out.html
И еще одна полезная тулза – dialog. Правда она не из портов, а идет в комплекте с системой. Предназначена для создания псевдо-графических диалогов. Команда
dialog --yesno "delete all files?" 7 60
покажет пользователю следующее:
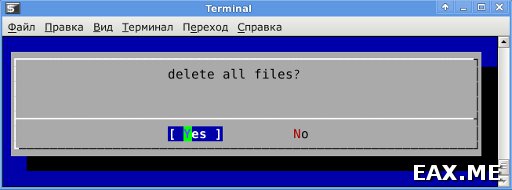
Если пользователь выберет «Yes», программа завершится с кодом 0, иначе – с кодом 1. Такую утилиту очень удобно использовать в скриптах.
Дополнение: Чуть не забыл про pwgen (/usr/ports/sysutils/pwgen) – консольный генератор легко запоминаемых паролей. Или трудно запоминаемых – смотря как запускать. Или не паролей, а временных имен файлов – смотря как использовать. В общем, штука полезная.
Дополнение: Мини заметки – выпуск 3