Мое решение задачи об олимпийских кольцах на Erlang
Принял участие в недавнем конкурсе по функциональному программированию и занял в нем первое место. В этой заметке вы найдете описание задачи, которую требовалось решить в рамках конкурса, а также мое решение этой задачи на языке программирования Erlang.
Постановка задачи была следующей.
Один восточный мудрец проникся духом Олимпийского движения и послал барону Пьеру де Кубертену ребус-шараду, в котором закодировал послание всем добрым людям мира.
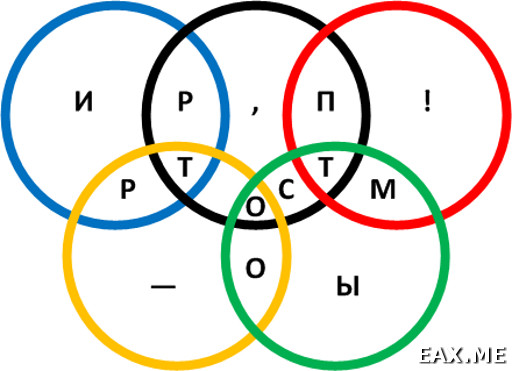
Но мудрец не был бы самим собой, если бы не сделал все это в виде математической головоломки. Как вы видите, здесь у нас есть диаграмма Венна, показывающее пересечение пяти множеств. Каждый сектор, образуемый пересечением, помечен буквой или каким-то иным символом, в том числе пробелом. Необходимо расставить числа от 1 до 15 в секторах таким образом, чтобы суммы чисел в каждом из пяти множеств, помеченных цветными кольцами, были равными друг другу. Это даст ключ к расшифровке послания.
Сразу привожу свое решение:
#!/usr/bin/env escript
-mode(compile).
main([]) ->
[ io:format("~s ~w~n", [Phrase, Order]) ||
Phrase <- phrase_list(word_list(), 15),
Order <- valid_orders(Phrase) ].
phrase_list(Words, Len) ->
[ Phrase || {phrase, Phrase} <- phrase_list("", Words, Len)].
phrase_list(Str, _Words, Len) when Len =:= 0 ->
[{phrase, Str}];
phrase_list(_Str, _Words, Len) when Len < 0 ->
[];
phrase_list(Str, Words, Len) when Len > 0 ->
lists:flatten([
phrase_list(NewStr, Words -- [W], Len - length(W))
|| W <- Words, NewStr <- [ W ++ Str ], valid_stat(NewStr)]).
valid_stat(Phrase) ->
Dict =
lists:foldl(
fun(L, Acc) ->
dict:store(L, dict:fetch(L, Acc) + 1, Acc)
end,
dict:from_list([{L,0} || L <- letter_list()]),
Phrase),
[I,R,T,Sp,Com,P,Ex,S,O,M,Y,Dash] =
[ dict:fetch(L, Dict) || L <- letter_list() ],
I =< 1 andalso R =< 2 andalso T =< 2 andalso
Sp =< 1 andalso Com =< 1 andalso P =< 1 andalso
Ex =< 1 andalso S =< 1 andalso O =< 2 andalso
M =< 1 andalso Y =< 1 andalso Dash =< 1.
valid_orders(Phrase) ->
Dict =
lists:foldl(
fun({L, Pos}, Acc) ->
dict:store(L, [Pos | dict:fetch(L, Acc)], Acc)
end,
dict:from_list([{L, []} || L <- letter_list()]),
lists:zip(Phrase, lists:seq(1,15))),
[[X1],R,T,[X8],[X3],[X4],[X5],[X10],O,[X12],[X15],[X13]] =
[ dict:fetch(L, Dict) || L <- letter_list() ],
lists:filter(
fun is_solution/1,
[{X1,X2,X3,X4,X5,X6,X7,X8,X9,X10,X11,X12,X13,X14,X15} ||
X2 <- R, X6 <- R, X1 =/= X6,
X7 <- T, X11 <- T, X7 =/= X11,
X9 <- O, X14 <- O, X9 =/= X14]).
is_solution({X1,X2,X3,X4,X5,X6,X7,X8,X9,X10,X11,X12,X13,X14,X15}) ->
Sum = X1 + X2 + X6 + X7,
X2 + X3 + X4 + X7 + X8 + X9 + X10 + X11 =:= Sum andalso
X4 + X5 + X11 + X12 =:= Sum andalso
X6 + X7 + X8 + X9 + X13 + X14 =:= Sum andalso
X14 + X9 + X10 + X11 + X12 + X15 =:= Sum.
letter_list() ->
[$i, $r, $t, $\s, $,, $p, $!, $s, $o, $m, $y, $-].
word_list() ->
[
"sport", " ", "-", ",", "!",
"o", "i", "ty", "my", "mir", "rim", "mor"
].
Теперь давайте попробуем разобраться, что к чему.
Честно говоря, первой моей идеей было использовать что-то вроде алгоритма A* с какими-нибудь хитрыми эвристиками и правилами отсечения для поиска подходящей комбинации из 15-и цифр. Однако нетрудно прикинуть, что пространство поиска в этом случае будет крайне велико, и какие-либо эвристики, по всей видимости, не особо помогут.
А что, если двигаться в обратном направлении? То есть, перебирать не цифры, а фразы на русском языке. На диаграмме мы видим 11 букв. Не думаю, что из них можно составить слишком много слов. Интуиция подсказывает, что поиск в таком пространстве решений будет намного быстрее.
Так что это могут быть за слова? «Тир», «рот», «мост», «пост», «ритм», «пир», «топор», «спор», «спорт»... Секундочку, «спорт»? Вот же оно! Это слово просто не может не использоваться в закодированной фразе после всей этой олимпийской символики. Что у нас осталось? Восклицательный знак, пробел, тире, запятая, а также шесть букв: «т», «и», «р», «м», «ы», «о». Совершенно очевидно, что восклицательный знак может стоять только в конце предложения. Также очевидно, что ни один из знаков препинания не стоит в начале предложения. С большой вероятностью между знаками препинания должны находиться буквы.
Какие слова можно получить из оставшихся шести букв? «Рим», «тир», «мир», «мор», «ты», «мы», «и», «о». Слово «ритм» явно не может использоваться, потому что в этом случае останутся буквы «ы» и «о», из которых нельзя получить ничего осмысленного. Кажется, уже можно переходить к перебору.
Объявим список «слов», из которых мы будем пытаться составить фразы:
word_list() ->
[
"sport", " ", "-", ",", "!",
"o", "i", "ty", "my", "mir", "rim", "mor"
].
Напишем функцию, которая генерирует из этих слов все возможные фразы заданной длины:
phrase_list(Words, Len) ->
[ Phrase || {phrase, Phrase} <- phrase_list("", Words, Len)].
phrase_list(Str, _Words, Len) when Len =:= 0 ->
[{phrase, Str}];
phrase_list(_Str, _Words, Len) when Len < 0 ->
[];
phrase_list(Str, Words, Len) when Len > 0 ->
lists:flatten([
phrase_list(NewStr, Words -- [W], Len - length(W))
|| W <- Words, NewStr <- [ W ++ Str ], valid_stat(NewStr)]).
Функция valid_stat используется для отсечения тупиковых ветвей поиска. Нет смысла продолжать строить фразу, если в ней, например, уже содержится две буквы «и»:
valid_stat(Phrase) ->
Dict =
lists:foldl(
fun(L, Acc) ->
dict:store(L, dict:fetch(L, Acc) + 1, Acc)
end,
dict:from_list([{L,0} || L <- letter_list()]),
Phrase),
[I,R,T,Sp,Com,P,Ex,S,O,M,Y,Dash] =
[ dict:fetch(L, Dict) || L <- letter_list() ],
I =< 1 andalso R =< 2 andalso T =< 2 andalso
Sp =< 1 andalso Com =< 1 andalso P =< 1 andalso
Ex =< 1 andalso S =< 1 andalso O =< 2 andalso
M =< 1 andalso Y =< 1 andalso Dash =< 1.
Функция main выводит на экран все найденные решения:
main([]) ->
[ io:format("~s ~w~n", [Phrase, Order]) ||
Phrase <- phrase_list(word_list(), 15),
Order <- valid_orders(Phrase) ].
Функция valid_orders собирает информацию о том, какие буквы во фразе на каких позициях находятся, после чего проверяет, являются ли эти позиции решением задачи:
valid_orders(Phrase) ->
Dict =
lists:foldl(
fun({L, Pos}, Acc) ->
dict:store(L, [Pos | dict:fetch(L, Acc)], Acc)
end,
dict:from_list([{L, []} || L <- letter_list()]),
lists:zip(Phrase, lists:seq(1,15))),
[[X1],R,T,[X8],[X3],[X4],[X5],[X10],O,[X12],[X15],[X13]] =
[ dict:fetch(L, Dict) || L <- letter_list() ],
lists:filter(
fun is_solution/1,
[{X1,X2,X3,X4,X5,X6,X7,X8,X9,X10,X11,X12,X13,X14,X15} ||
X2 <- R, X6 <- R, X1 =/= X6,
X7 <- T, X11 <- T, X7 =/= X11,
X9 <- O, X14 <- O, X9 =/= X14]).
Функция is_solution принимает вектор из 15-и цифр и проверяет, является ли он искомым:
is_solution({X1,X2,X3,X4,X5,X6,X7,X8,X9,X10,X11,X12,X13,X14,X15}) ->
Sum = X1 + X2 + X6 + X7,
X2 + X3 + X4 + X7 + X8 + X9 + X10 + X11 =:= Sum andalso
X4 + X5 + X11 + X12 =:= Sum andalso
X6 + X7 + X8 + X9 + X13 + X14 =:= Sum andalso
X14 + X9 + X10 + X11 + X12 + X15 =:= Sum.
На моем компьютере программа находит решение примерно за одну минуту. Закодированной фразой было:
О спорт,ты-мир!
... а вписывать цифры следовало примерно следующим образом:
13 6 8 4 15
14 7 2 1 3 9 12
11 5 10
Например, в левом верхнем круге должны находится цифры 13, 6, 7 и 14.
Что интересно, программе удалось найти второе решение, фразу:
О спорт,ты-Рим!
Попробуйте на досуге объяснить этот феномен.
На этом у меня все. Как обычно, если во время чтения заметки у вас возникли какие-то вопросы, я буду рад ответить на них в комментариях. Участвуйте в конкурсах по программированию, это полезно и весело!