Профилирование в Go (гостевой пост Владимира Солонина)
Рантайм Go содержит встроенный профайлер, но по умолчанию он выключен. Существует несколько способов его эксплуатации, самый «низкоуровневый» – через библиотеку runtime/pprof. Russ Cox, один из главных разработчиков Go, разместил хорошую статью по ее использованию. Однако я бы порекомендовал пакет-обертку profile, он чуть проще в настройке.
Важно! Данная статья потеряла актуальность и представляет разве что историческую ценность. Описанный в ней профайлер прекратил свое существование.
Для начала его надо установить:
go get github.com/davecheney/profile
Теперь нужно внести его в список импорта и активировать профайлер в начале функции main:
import "github.com/davecheney/profile"
func main() {
//запустит CPU-профайлер
defer profile.Start(profile.CPUProfile).Stop()
// ...
}
Чтобы изменить некоторые опции или активировать другие счетчики, можно использовать расширенную форму:
func main() {
config := profile.Config{
CPUProfile: true,
MemProfile: true,
BlockProfile: true,
ProfilePath: "./pro",
}
defer profile.Start(&config).Stop()
// ...
}
Здесь я активировал все три вида счетчиков, доступных в этой библиотеке, и изменил каталог для записи профайлов относительно каталога запуска. Но вообще так делать не рекомендуется. Лучше запускать по одному, поскольку несколько работающих счетчиков снижают точность результатов. Теперь осталось собрать программу с помощью go build и запустить. В ProfilePath появятся три файла: block.pprof, cpu.pprof и mem.pprof.
Сначала рассмотрим CPU-профайлер. Вывод визуализированной информации в браузер в виде графа:
go tool pprof -web ./your_bynary ./pro/cpu.pprof
В системе должен быть установлен Graphviz.
Сохранение графического представления в заданный файл, доступны форматы png, svg, pdf, ps, gif:
go tool pprof -gif ./your_bynary ./pro/cpu.pprof > cpu.gif
Запуск интерактивной оболочки:
go tool pprof ./your_binary ./pro/cpu.pprof
Здесь после приглашения (pprof) попробуйте ввести команду top. Она выведет функции, вызванные вашей программой, в порядке убывания времени выполнения. Для многопоточной программы из моего предыдущего поста это выглядит так:
(pprof) top
53.38s of 53.85s total (99.13%)
Dropped 2 nodes (cum <= 0.27s)
Showing top 10 nodes out of 13 (cum >= 0.37s)
flat flat% sum% cum cum%
20.81s 38.64% 38.64% 40.44s 75.10% crypto/md5.(*digest).Write
18.78s 34.87% 73.52% 18.78s 34.87% crypto/md5.block
6.45s 11.98% 85.50% 45.17s 83.88% crypto/md5.(*digest).checkSum
1.99s 3.70% 89.19% 49.95s 92.76% crypto/md5.Sum
1.39s 2.58% 91.77% 1.76s 3.27% main.nextPass
1.20s 2.23% 94.00% 53.84s 100% main.worker
1.07s 1.99% 95.99% 1.07s 1.99% runtime.duffzero
0.85s 1.58% 97.57% 0.85s 1.58% runtime.memmove
0.47s 0.87% 98.44% 0.93s 1.73% runtime.memequal
0.37s 0.69% 99.13% 0.37s 0.69% main.nextByte
Первые две колонки показывают время выполнения каждой функции в секундах и в процентах. Третья колонка содержит суммарное время выполнения функций, начиная сверху. Четвертая и пятая колонки показывают полное время выполнения каждой функции, включая время ожидания возврата из других функций, чем и отличаются от первых двух. По умолчанию вывод сортируется по первым столбцам. Это можно изменить, дополнив команду top опцией -cum. Хочу обратить внимание, что вывод основан не на реальном времени, а на процессорном. Оно составляет сумму интервалов работы каждого ядра. Не удивляйтесь также, если не все функции будут выведены в списке или на диаграмме. Быстрые и редко вызываемые функции могут быть отброшены, как незначительные.
Для программ с большим количеством функций полезна будет команда topN, где N – любое натуральное число. Например, top7 выведет первые 7 строк.
В интерактивном режиме также легко вывести графическое представление программы в браузер, для этого выполните команду web, или для сохранения в файл – png > cpu.png:
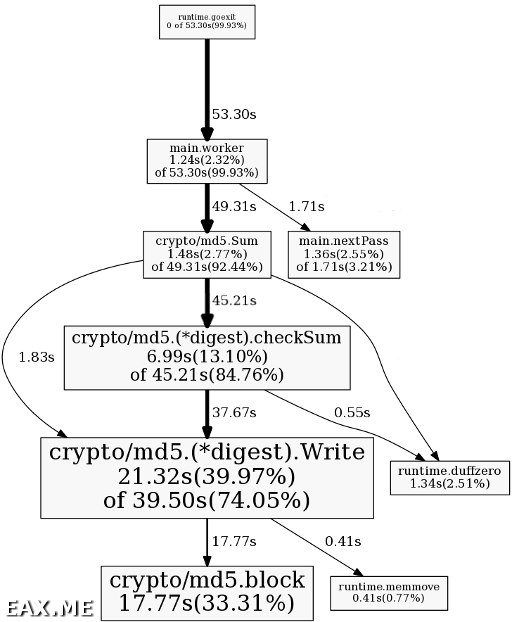
С помощью команды list или ее аналога weblist можно рассмотреть любую функцию в деталях. Вбейте, например, list worker, и вывод покажет, какие участки функции worker (точнее тех функций, что подходят под это регулярное выражение) выполняются достаточно долго:
(pprof) list worker
Total: 53.34s
ROUTINE ======================== main.worker in main.go
1.24s 53.30s (flat, cum) 99.93% of Total
. . 42: var p part
. . 43: var b []byte
. . 44: for {
. . 45: p = <-in
. . 46: b = []byte(p.start)
80ms 80ms 47: for b[0] != p.end {
1.09s 51.44s 48: if md5.Sum(b) == hash {
. . 49: out <- string(b)
. . 50: return
. . 51: }
70ms 1.78s 52: nextPass(b)
. . 53: }
. . 54: }
. . 55:}
. . 56:
. . 57:func generator(in chan<- part) {
Команда disasm function аналогичным образом позволяет получить ассемблерный листинг. Команда web function покажет в браузере часть графа, относящуюся в выбранной функции.
По умолчанияю профайлер разделяет статистику по функциям (--functions), но это можно изменить с помощью параметров запуска: -files, -lines, -addresses сделают разбиение пофайловым, построчным и поадресным соответственно.
Используйте команду help в интерактивном режиме или параметр командной строки -h, чтобы узнать об остальных возможностях профайлера.
Профайлер памяти имеет несколько дополнительных опций:
- -inuse_space – показывает количество памяти, занятое в текущий момент (для работающих приложений), применяется по умолчанию;
- -inuse_objects – то же самое, но показывает количество объектов;
- -alloc_space – показывает количество памяти, выделенное за все время работы программы;
- -alloc_objects – аналогично, только для объектов;
Количество выделенных в памяти объектов важно еще тем, что влияет на производительность приложения, поскольку чем больше аллокаций, тем больше работы у сборщика мусора.
Запуск в интерактивном режиме:
go tool pprof -alloc_space ./your_binary ./pro/mem.pprof
или:
go tool pprof -alloc_objects ./your_binary ./pro/mem.pprof
В остальном работа с профайлером памяти мало чем отличается от таковой для CPU-профайлера, за исключением того, что вместо времени работы ядра процессора учитывается количество выделенной памяти или объектов.
Профайлер блокировок позволяет увидеть, где в программе происходят остановки горутин из-за блокировок, вызванных объектами синхронизации, такими как каналы, мьютексы и т.д.
Запуск в интерактивном режиме:
go tool pprof ./your_binary ./pro/block.pprof
Сами блокировки не всегда являются поводом для беспокойства, поскольку нижележащий поток операционной системы в таком случае переключается на другую горутину. Но есть возможность простоя, если работающих горутин меньше, чем ядер процессора. Также надо учитывать и дороговизну частых блокировок/разблокировок.
Другой способ активации профайлера удобен для веб-приложений и других программ с длительным или произвольным временем работы. Для этого используется пакет net/http/pprof. Он позволяет анализировать характеристики приложения, не прерывая его работу. Сначала нужно импортировать следующие пакеты:
import (
_ "net/http/pprof"
"net/http"
"log"
)
Символ _ перед названием пакета означает, что сам он не будет импортирован, но будет выполнена инициализация переменных и выполнена init-функция этого пакета, которая, в данном случае, регистрирует несколько обработчиков в стандартном web-сервере Go.
Кроме того, необходимо добавить несколько строк в начало функции main:
func main() {
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
// ...
}
Этот код запускает в отдельной горутине web-сервер Go, с помощью которого собранная информация будет отображаться в браузере. Соберите программу с помощью go build и запустите.
Следующая команда запустит 30-секундный сбор информации об использовании процессора, по окончании которого запустит CPU-профайлер в интерактивном режиме:
go tool pprof http://localhost:6060/debug/pprof/profile
А эта команда запустит профайлер памяти:
go tool pprof http://localhost:6060/debug/pprof/heap
Профайлер блокировок:
go tool pprof http://localhost:6060/debug/pprof/block
У меня он, правда, выдал ошибку parsing profile: unrecognized profile format, но, может быть, вам повезет.
Увидеть всю доступную статистику в «сыром» виде можно по адресу:
http://localhost:6060/debug/pprof/
Дополнительную информацию об использовании профайлера, а также о техниках оптимизации Go-кода, можно найти в замечательной статье Дмитрия Вьюкова, еще одного разработчика Go.
От себя я хочу уже в который раз поблагодарить Владимира за то, что он не перестает радовать нас гостевыми постами о языке Go, а также призвать читателей задавать вопросы и предлагать темы для будущих статей.
Дополнение: Go и работа с базами данных, в частности с PostgreSQL