Ломаем капчу – вычищаем мусор и нарезаем на буквы
Продолжаем ломать капчу. На предыдущем шаге мы с вами произвели сбор и предварительный анализ данных. В результате сложилось некоторое понимание того, как работает исследуемая капча, а также образовалось множество примеров изображений с известными кодами на них. Следующим шагом мы нарежем нашу капчу на буквы.
Для начала – небольшая иллюстрация того, как это будет работать в итоге:
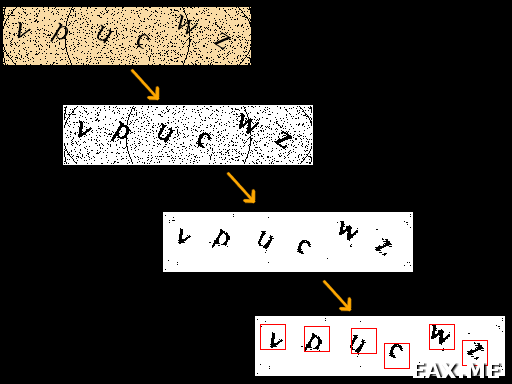
Теперь перейдем к реализации.
На этом этапе нам понадобится язык программирования Haskell, пакет JuicyPixels, а также пакет JuicyPixels-util. Кое-кто из вас может помнить, как мы использовали первый пакет, когда работали с текстурами в Haskell'ном OpenGL. Из него, помимо прочего, нам понадобится функция readImage, которая считывает и декодирует картинку в одном из множества поддерживаемых форматов (BMP, JPG, GIF, PNG):
readImage :: FilePath -> IO (Either String DynamicImage)
Из пакета JuicyPixels-util мы воспользуемся функцией, которая преобразует любую декодированную картинку в формат RGBA8:
fromDynamicImage :: DynamicImage -> Image PixelRGBA8
Имея цветное изображение в RGBA8 и зная цвет фона (он всегда одинаковый), не представляет большого труда преобразовать его в черное-белую картинку, заодно избавившись от черной рамки в один пиксель:
isBorder x y = x == 0 || x == 249 || y == 0 || y == 59
white = 255 :: Pixel8
black = 0 :: Pixel8
backgroundColor = PixelRGBA8 249 219 165 255
imageToWhiteAndBlack :: Image PixelRGBA8 -> IO (Image Pixel8)
imageToWhiteAndBlack img =
withImage 250 60 $
\x y -> return $
let px = pixelAt img x y in
if isBorder x y || px == backgroundColor
then white
else black
Обратите внимание, как, благодаря ленивым вычислениям, мы можем не писать лишний раз вложенных if-then-else, чтобы сэкономить на вызове pixelAt.
Вычистить мусор также несложно следующим образом:
removeNoise :: Image Pixel8 -> IO (Image Pixel8)
removeNoise img = do
let getSum im x y =
if isBorder x y
then 255
else sum [ fromIntegral (pixelAt im i j) :: Int
| i <- [x-1..x+1], j <- [y-1,y+1] ] `div` 9
withImage 250 60 $ \x y -> return $
if getSum img x y > 64 then white
else black
Здесь для каждого пикселя рассматривается квадрат 3x3 с заданным пикселем по центру. Если усредненный цвет в этом квадрате светлее заданного оттенка серого, подобранного эмпирическим путем, считается, что этот пиксель – часть мусора и он заменяется на белый. Иначе делается предположение, что пиксель принадлежит крупному скоплению черных пикселей, коими являются буквы, и пиксель окрашивается в черный цвет. Оказалось, что такой вот простой алгоритм вычищает мусор просто отлично.
Далее нам нужно разделить картинку на шесть независимых изображений каждой буквы на ней. Учитывая, что все буквы идут слева направо и между ними имеется куча свободного места, не составляет труда придумать специализированный для данной капчи алгоритм, который будет не только правильно разделять капчу на отдельные буквы, но и определять угол наклона букв, благодаря чему правильно нормализовать их, то есть, избавляться от наклона. Более того, поскольку буквы не искажаются, можно просто взять 15 эталонных изображений букв и тем или иным видом перебора найти их позиции и углы наклона. Тем более, что известно, что угол наклона у всех букв одинаковый. Таким образом, мы не только разобьем изображение на буквы, но и моментально определим сами эти буквы.
Однако я решил использовать более универсальный алгоритм. Он применим даже в случае, если буквы имеют разный наклон, могут быть расположены почти одна под другой, написаны различными шрифтами и иметь всяческие искажения. Что позволяет добиться такой универсальности? Ну конечно же генетические алгоритмы! Если внимательно присмотреться к третьей сверху капче на ранее приведенной иллюстрации, оказывается, что буквы образуют как бы шесть изолированных черных пятен. Наша задача сводится всего навсего к тому, чтобы разместить на картинке шесть квадратов фиксированного размера таким образом, чтобы (1) они не пересекались (2) суммарное количество черных пикселей во всех квадратах было максимальным.
Здесь я не буду приводить код программы, которая нарезает капчу на буквы, потому что он довольно тривиален. При размере квадрата 25x25, размере популяции равном 50 особям и вероятности мутации (при которой один квадрат смещается на ±20 пикселей по вертикали и горизонтали) равной 0.5 алгоритм замечательно сходится за 7-8 поколений.
Теперь мы научились получать изображение каждой буквы по отдельности. Кроме того, благодаря предыдущему шагу, мы знаем, какие именно буквы изображены на каждой капче. Осталось всего лишь научиться распознать буквы, и дело в шляпе! Но это уже тема следующего поста. Следите за обновлениями.
Дополнение: Ломаем капчу – распознавание символов при помощи многослойной нейронной сети