Памятка по Riak – часть первая, теоретическая
Настало время разобраться, что представляет собой Riak, как установить и настроить его в Ubuntu Linux, а также узнать, как использовать некоторые его возможности через REST API. Эта памятка не заменит вам чтения книг по Riak, но поможет составить общее впечатление об этой СУБД.
Коротко о главном:
- Riak – это масштабируемая распределенная отказоустойчивая key-value СУБД. Ключ и значение представляют собой просто строки. Однако ничто не мешает сохранить в качестве значения произвольный объект, сериализованный в JSON, MessagePack или иной формат;
- Является приложением с открытым исходным кодом, написанным преимущественно на Erlang;
- В Riak нет единой точки отказа. Все ноды в кластере являются равноправными, нет никаких master'ов и slave'ов. Данные в Riak сегментируются между нодами автоматически. Если кластер перестал справляться с нагрузкой, нужно просто добавить новую ноду, а Riak сделает решардинг самостоятельно. Также данные автоматически дублируются на нескольких нодах. За счет этого, если одна из нод вышла из строя, ее можно не спеша заменить;
- Riak является весьма гибкой системой. В зависимости от ценности данных, мы можем хранить их на большем или меньшем количестве узлов. Также мы можем увеличить скорость чтения данных ценой снижения скорости записи, и наоборот;
- Общение с СУБД возможно с помощью REST API и Protobuf. Первый вариант удобен для использования людьми, например, при отладке, второй является более быстрым и используется в драйверах для многих языков программирования;
- Поддерживается несколько бэкендов для хранения данных – Bitcask, LevelDB и Memory. В старых версиях Riak также был бэкенд Innostore, основанный на InnoDB, но он больше не поддерживается. Также есть специальный бэкенд Multi, речь о котором пойдет ниже;
- В Riak поддерживаются линки и link walking. Это что-то вроде внешних ключей из мира РСУБД;
- При использовании LevelDB доступны вторичные индексы, они же 2i. Вторичные индексы бывают двух типов – числа и строки. Есть поиск по точному значению и диапазону значений. Работают 2i аналогично вторичным индексам в мире РСУБД;
- Поддерживается MapReduce. Код map- и reduce-функций можно писать на JavaScript или Erlang. Если провести параллель с миром РСУБД, то в первом приближении MapReduce соответствует group by;
- В Riak есть полнотекстовый поиск, так называемый Riak Search;
- Поддерживаются precommit и postcommit хуки, своего рода аналоги триггеров из РСУБД;
- Существует отдельное приложение, Riak CS (Cloud Storage), для хранения в Riak больших файлов. Большой файл – это от 1 Мб до 5 Гб. Файлы, имеющие размер в пределах 1 Мб, можно хранить просто в Riak;
- Есть веб-админка, называется Riak Control;
- Riak Enterprise – это платная версия Riak с коммерческой поддержкой 24x7 от Basho (компании-разработчика), наличием репликации по SSL между дата-центрами, а также SNMP и JMX;
- Riak используется в Google, GitHub, AOL, Dell, Wikia, BazQux и не только;
Как же это работает? При настройке Riak в конфиге указывается некое число, называемое количеством партиций. Это число должно быть степенью двойки. Допустим, мы выбрали число 32. При чтении и записи данных от ключа берется SHA1. Таким образом, любому ключу ставится в соответствие число от 0 до 2160-1. Если число попало в интервал от 0 до 2160/32-1, оно относится к первой партиции, если от 2160/32 до 2*2160/32-1, то ко второй и так далее.
Партиции хранятся на виртуальных нодах (vnode). Количество виртуальных нод равно количеству партиций. Каждая физическая нода отвечает за работу примерно равного количества виртуальных нод. Например, если наш кластер состоит из четырех узлов, на каждом будет находится 8 vnode'ов.
В графическом виде это можно представить следующим образом:
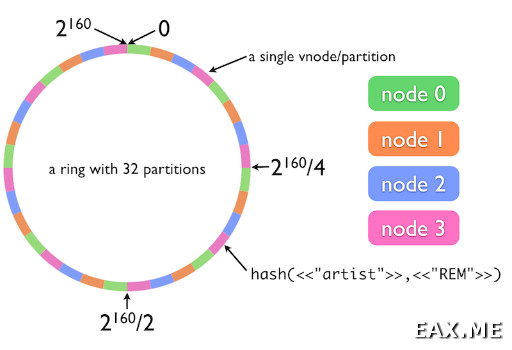
Во время записи данные пишутся не на одну ноду, а на некоторое заданное количество N. По умолчанию N равно трем, но может быть переопределено на уровне корзины (о корзинах речь пойдет ниже). Например, если после вычисления SHA1 выяснилось, что данные относятся к 7-й партиции, они будут записаны на 7-ю, 8-ю и 9-ю vnode, за работу которых отвечают 3-я, 0-я и 1-я физические ноды соответственно. Таким образом, даже если часть машин выйдет из строя, мы все еще будем иметь доступ ко всем данным.
Информация о том, какая нода за работу каких vnode отвечает, хранится в некой таблице. Ноды периодически обмениваются друг с другом этой таблицей (см gossip protocol), поддерживая ее тем самым в актуальном состоянии.
При добавлении в кластер новой ноды, она запрашивает таблицу у ноды, уже находящейся в кластере (seed node) и добавляет себя в таблицу таким образом, чтобы каждая нода отвечала за работу примерно равного количества vnode'ов и физические ноды чередовались в кольце, как на приведенной картинке. Затем нода отправляет таблицу в кластер, где она довольно быстро разлетается между нодами. Получив обновленную таблицу, ноды передают новой ноде данные, на которые она заявила права.
Продолжение следует...