Параллелизм в Haskell (гостевой пост Романа Соколовского)
Предыстория. Некоторое время назад в комментариях к заметке Работа с нитями/потоками в Haskell Роман совершенно справедливо заметил, что задачу перебора хэшей было бы куда правильнее решать, используя, например, пакет parallel. Перебор хэшей был выбран мной, как универсальная задача, с помощью которой можно продемонстрировать работу и с MVars, и с транзакционной памятью, и с монадами Par/Eval. Чтобы не приходилось придумывать новую задачу для каждого нового поста.
Но Роман прав в отношении того, что такой подход вносит неразбериху, поскольку STM и Par предназначены для решения разных проблем, и демонстрационные задачи следовало бы выбрать соответствующие. Затем Роман послал мне пуллреквест с кодом программы, решающей ту же задачу перебора хешей с использованием пакета parallel. На что я ответил, дескать, ну раз ты опередил меня с кодом, пиши гостевой пост, а то мне писать пост с описанием чужого кода как-то несподручно :) Ну Роман его и написал. Передаю ему слово.
Гонка за тактовую частоту процессора завершилась. Вам нужно, чтобы программа работала быстрее? Добро пожаловать в темный и опасный мир многопоточности, fork/join, блокировок и недетерминизма. Ваш крестовый поход по минному полю начался. Граната уже в руках у обезьяны. Дуло уже направлено в ногу. Все остальное – лишь вопрос времени.
Программисты любят чистые функции. Чистота – это надежность, легкость в тестировании и комбинировании. Где, как не в сообществе чистых функиональных языков острее почувствуют боль от потери ссылочной прозрачности (referential transparency) из-за необходимости ускорения вычислений?
В этой заметке мы обсудим отличия параллелизма (parallelism) от многопоточности (concurrency). Далее мы познакомимся с инструментами параллельного программирования в Haskell, позволяющими ускорять чистые вычисления без потери ссылочной прозрачности. Наконец, мы применим наши знания и распараллелим уже рассмотренную ранее задачу поиска пароля по хеш-функции.
Parallelism vs concurrency
Большая часть языков не проводит различия между параллельными вычислениями и многопоточностью, предоставляя для них единый инструментарий. В Haskell для каждой из этих задач свой набор инструментов и абстракций. Разберемся, что такое параллелизм и многопоточность и в чем их фундаментальное различие.
Параллельная программа использует множественность вычислительных единиц (процессоров, ядер, GPU и т.д.) для ускорения вычисления. Мы разделяем работу между одновременно работающими вычислителями в надежде, что выигрыш от параллелизма превзойдет дополнительные расходы на него. Ускорение вычисления – единственная цель параллелизма.
Многопоточность, напротив, – это использование в одной программе нескольких потоков управления. Эти потоки выполняются «одновременно» в том смысле, что побочные эффекты потоков перемежаются между собой. Задачей многопоточного программирования является сохранение модульности в случае одновременного взаимодействия с несколькими внешними агентами (пользователь, база данных и пр). Количество процессоров в данном случае не имеет значения.
Таким образом, для параллелизма нужны несколько вычислителей, а для многопоточности – побочные эффекты.
Понятие «потоков управления» лишено смысла в контексте чистого вычисления, ведь в нем нет побочных эффектов. Таким образом, многопоточность имеет смысл только в контексте монады IO. Более того, многопоточные вычисления фундаментально недетерминированны, потому что их задачей является взаимодействие с внешними агентами. А где недетерминизм, там и боль в отладке, тестировании и поддержке.
Основы параллелизма в Haskell
Не очень-то хочется терять детерминированность просто потому, что мы хотим ускорить чистое вычисление. Хочется решать настоящие задачи параллельных вычислений: гранулярность, зависимость по данным. Haskell обеспечивает программиста средствами детерминированного параллельного программирования. Они позволяют ускорить чистое вычисление, не теряя при этом самой чистоты.
Чистую по-сути задачу можно распараллелить и средствами многопоточного программирования, как вы могли убедиться в статье про работу с потоками в Haskell. Тем не менее, не стоит терять чистоту без крайней на то необходимости.
К делу! Сегодня мы будем пользоваться пакетом parallel, центральным понятием которого являются Parallel Strategies. Parallel Strategy – это правило вычисления санка (thunk). Результат применения стратегии к санку – это вычисление в монаде Eval, которое мы можем выполнить, вызвав runEval:
data Eval a
instance Monad Eval
runEval :: Eval a -> a
type Strategy a = a -> Eval a
Имеется несколько базовых стратегий вычисления: rpar, rseq, rdeepseq. Первые две стратегии вычисляют аргумент до Weak Head Normal Form (до первого конструктора). Функция rpar запускает вычисление до WHNF параллельно:
rpar :: Strategy a -- sparks evaluation to WHNF
rseq :: Strategy a -- WHNF
rdeepseq :: NFData a => Strategy a -- forces to NF
Другие стратегии и больше подробностей можно найти в Control.Parallel.Strategies.
Наконец, посмотрим на пару вспомогательных функций, которыми мы воспользуемся далее для решения задачи. Комбинатор using позволяет удобно и лаконично прикреплять стратегии к санкам. Функция parList параллельно вычисляет каждый элемент списка, используя переданный параметр для вычисления отдельного элемента.
using :: a -> Strategy a -> a
x `using` s = runEval (s x)
parList :: Strategy a -> Strategy [a]
Теперь у нас есть все для параллельного вычисления элементов списка, например:
map f xs `using` parList rdeepseq :: [a]
Данное выражение означает, что мы параллельно применяем функцию f к каждому элементу списка, полностью вычисляя результат.
Вот и все! Не нужно никаких fork/join, мы не потеряли детерминированность, все тесты по-прежнему работают. Фундаментально задача распараллеливания вычислений проще не стала, но мы избавились от огромного источника случайной сложности (сущность и акциденция, или серебряной пули нет).
Как это работает
Я начинаю нервничать, когда пользуюсь инструментом, внутреннее устройство которого мне не известно хотя бы приблизительно. Так что давайте приоткроем крышку черного ящика и хоть одним глазком посмотрим под капот.
При вычислении rpar среда времени выполнения (Runtime System, RTS) создает так называемый spark (англ. вспышка) и помещает его в очередь – spark pool. Каждый спарк содержит ссылку на санк, который необходимо вычислить. Далее по мере освобождения очереди задач Capability (виртуальный CPU; эффективнее всего иметь по Capability на «настоящий» CPU) планировщик потребляет спарки из пула и создает для каждого спарка свой легковесный поток. Этот легковесный поток помещается в очередь задач (run queue) и осуществляет вычисление нашего санка. Таким образом, Parallel Haskell можно рассматривать как систему worker'ов и очередей, где рабочими являются нативные потоки операционной системы, а организацию и управление всем этим бедламом RTS берет на себя.
Тех, кому хочется залезть под капот с головой, направляю в GHC Commentary и GHC User's Guide.
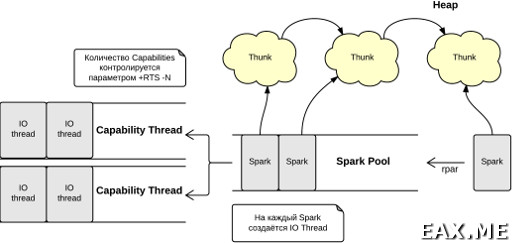
Потоки, используемые для параллельных вычислений, ничем не отличаются от потоков, которые вы создаете с помощью forkIO. Важность инструментов параллельного программирования заключается не во внутренностях реализации, а в гарантии детерминированности. parMap f xs всегда будет давать тот же результат, что и map f xs с оглядкой на throw, undefined и пр.
Теперь, когда мы познакомились с внутренним механизмом параллельных вычислений в Haskell, нетрудно прочувствовать всю суть проблемы гранулярности (granularity). Накладные расходы на создание и манипуляции со спарками не должны превышать бенефит от параллелизма. С другой стороны, если спарков слишком мало и время работы над спарками распределено сильно неравномерно, то мы можем столкнуться с простаиванием процессоров.
Давайте же наконец применим новые знания в деле!
Играем в крутых хакеров
Давайте в очередной раз почувствуем себя на месте плохих мальчиков, которым попали в руки важные сведения. Например, хешированные пароли, которые нужно взломать. Для простоты положим, что длина пароля известна. Строго говоря, перед нами стоит задача поиска прообраза хеш-функции.
Будучи высококлассными специалистами в области криптографии, мы решаем использовать метод полного перебора по паролям нужной длины. Для каждого возможного пароля будем получать его хеш и проверять, имеется ли полученный хеш в списке украденных. Если да, то запоминаем пару пароль-хеш для дальнейшего злонамеренного использования.
Давайте для начала реализуем перебор последовательно:
main :: IO ()
main = do
let hashList = [
-- 1234
"03ac674216f3e15c761ee1a5e255f067953623c8b388b4459e13f978d7c846f4",
-- r2d2
"8adce0a3431e8b11ef69e7f7765021d3ee0b70fff58e0480cadb4c468d78105f"
]
pwLen = 4
charList = ['0'..'9'] ++ ['a'..'z']
allPasswords = replicateM pwLen charList
matched = filterMatched hashList allPasswords
mapM_ (putStrLn . showMatch) matched
where showMatch (pw, h) = pw ++ ":" ++ h
Обратите внимание на allPasswords = replicateM pwLen charList. Функция replicateM определена над любой монадой; для списковой монады она генерирует все возможные варианты списков указанной длины, где на каждой позиции значения пробегают элементы исходного списка, например:
> replicateM 2 [0, 1]
[[0,0],[0,1],[1,0],[1,1]]
То, что нужно! Чтобы понять, как это работает, попробуйте рассмотреть список как недетерминированное значение. Вообще, медитирование над списковой монадой может даровать просветление. Обязательно займитесь этим на досуге! Но пора снова возвращаться к нашим грязным делишкам.
Мы не определили, что означает filterMatched. Эта функция – типичный map/reduce:
import Bruteforce.Common( hash )
type Hash = String
type Password = String
filterMatched :: [Hash]
-> [Password]
-> [(Password, Hash)]
filterMatched knownHashes candidates =
filter (elemOf knownHashes . snd) pwHashList
where hashes = map hash candidates
pwHashList = zip candidates hashes
elemOf = flip elem
Список всех возможных паролей генерируется на ходу, мы не храним целиком в памяти ни его, ни список хешей. Ленивость Haskell позволила нам добиться модульности (генерация паролей и фильтрование разделены между собой; в языках с аппликативным порядком вычисления мы должны были бы пользоваться итераторами, генераторами и прочими дарами богов). Подробнее про удивительные взаимоотношения ленивости и модульности читайте в статье за авторством John Hughes.
На моем компьютере с Intel Core i7-2600K @ 3.4GHz на борту данное творение перебрало все четерехбуквенные пароли за 12.9 секунд. Крутые хакеры ждать не любят! Но вместо того, чтобы гоняться за линейной эффективностью, мы займемся распараллеливанием задачи.
Раскидать задачу по процессорам должно быть очень просто, ведь у нас нет никакой зависимости по данным. Прежде, чем подумать головой, я приказываю компьютеру параллельно вычислить фильтрование:
filter (elemOf knownHashes . snd) pwHashList
`using` parList rdeepseq
Собираю программу с флагом -threaded и запускаю с параметром +RTS -N4. От параллелизма никакого толку! Потом я осознаю, что filter – это операция свертки, которая пробегает весь список pwHashList последовательно, и от моего приказа параллельно вычислить результат свертки сам аргумент параллельно вычисляться не станет. Ну что же, попробуем параллельно вычислить pwHashList:
pwHashList = zip candidates hashes
`using` parList rdeepseq
Все снова напрасно. Сами пароли и хеши мы теперь генерируем параллельно, но фильтруем результирующий список все равно последовательно. К тому же, теперь все возможные пароли и хеши хранятся у нас в памяти, ведь мы потеряли ленивость. Неудача.
Через какое-то время раздумий прихожу к выводу, что нужно сохранить ленивость, при этом фильтрование результатов тоже должно проходить параллельно. Единственное решение, пришедшее на ум – нужно алгоритмически разбить пространство паролей на множества достаточно солидного размера и запустить вычисление всего filterMatched параллельно для каждого такого множества. После этого мы объединим результаты в один с помощью concat.
Последний элемент головоломки: как алгоритмически генерировать подмножества паролей? По аналогии с решением из прошлой статьи, сначала сгенирируем префиксы определенной длины (длина префикса будет контролировать гранулярность), и к каждому префиксу припишем все возможные остатки. Пароли с общим префиксом будут объединены в множества, которые будут обрабатываться параллельно:
type CharList = String
groupedPasswords :: Int -> Int -> CharList -> [[Password]]
groupedPasswords totalLen prefLen charList =
map (prependPrefix postfixes) prefixes
where prefixes = replicateM prefLen charList
postfixes = replicateM restLen charList
restLen = totalLen - prefLen
prependPrefix post prefix = map (prefix ++) post
Проверим в ghci:
> groupedPasswords 3 1 "ab"
[["aaa","aab","aba","abb"],["baa","bab","bba","bbb"]]
> groupedPasswords 3 2 "ab"
[["aaa","aab"],["aba","abb"],["baa","bab"],["bba","bbb"]]
Похоже на правду. Но мы на этом не остановимся и протестируем код QuickCheck'ом. Проверим, что groupedPasswords действительно осуществляет разбиение пространства ключей, то есть мы ничего не потеряли и не включили дважды:
-- concat (groupedPasswords a b (b <= a) lst) == replicateM a lst
prop_groupconcat :: Property
prop_groupconcat =
forAll (choose (0, 6)) $ \totalLen ->
forAll (choose (0, totalLen)) $ \prefLen ->
concat (groupedPasswords totalLen prefLen charList) ==
replicateM totalLen charList
where charList = ['0' .. '9']
Числа подобраны так, чтобы компьютер не умер от перенапряжения в процессе тестирования, ведь мы имеем дело с комбинаторным ростом количества паролей.
Заметьте, что в прошлой статье генерирование префикса и генерирование остатка находились в разных местах программы (и выполнялись в разных потоках управления), это было сквозным функционалом. А где сквозной функционал, там сложность в поддержке, понимании и тестировании кода. Мы бы не смогли так просто взять и написать тест, аналогичный приведенному.
Осталось только склеить кусочки воедино и посмотреть на результаты:
filterMatchedPar :: Int
-> CharList
-> [Hash]
-> [(Password, Hash)]
filterMatchedPar pwLen charList knownHashes = concat matched
where prefLen = 1
grouped = groupedPasswords pwLen prefLen charList
matched = map (filterMatched knownHashes) grouped
`using` parList rdeepseq
Наконец, main почти ничем не отличается от приведенного выше, просто мы используем параллельную версию функции взлома паролей вместо последовательной. Для полноты картины все равно приведем main целиком:
main :: IO ()
main = do
let hashList = [
-- 1234
"03ac674216f3e15c761ee1a5e255f067953623c8b388b4459e13f978d7c846f4",
-- r2d2
"8adce0a3431e8b11ef69e7f7765021d3ee0b70fff58e0480cadb4c468d78105f"
]
pwLen = 4
charList = ['0'..'9'] ++ ['a'..'z']
matched = filterMatchedPar pwLen charList hashList
mapM_ (putStrLn . showMatch) matched
where showMatch (pw, h) = pw ++ ":" ++ h
Готово. На моей машине конечная версия отрабатывает за 3.6 секунды, чуть быстрее многопоточной версии из прошлой статьи. Значит, мы получили лучшее от двух миров: скорость и чистоту! Это определенно победа.
Послесловие
Мы рассмотрели лишь один из инструментов параллельного программирования в Haskell, в котором акцент делается на ленивых вычислениях. Альтернативным решением было бы воспользоваться пакетом monad-par, который предоставляет больший контроль над процессом вычисления в рамках dataflow-parallelism. Там мы бы работали с подобием C++ future или Haskell async для явного выражения зависимостей по данным. Сегодня нам такие сложности не понадобились.
Если бы мы собирались молотить большие массивы данных, мы бы воспользовались параллельными массивами REPA или даже перенесли бы вычисление на GPU c помощью accelerate.
Data Parallel Haskell – это исследовательский проект, который концентрируется на вложенном параллелизме (nested data parallelism), в данное время находящийся на стадии разработки. Возможно, когда-нибудь DPH тоже пополнит инструментарий программиста на Haskell.
Большая часть этих инструментов рассматривается в прекрасной книге Саймона Марлоу «Parallel and Concurrent Programming in Haskell», которую я от души советую каждому встречному.
Весь код, тест(-ы) и исходник этой статьи доступны в этом архиве. Сам я доступен по почте (sokolovskiy.roman гав gmail.com) или через ВК и с радостью отвечу на ваши вопросы.
От себя я хочу сказать огромное спасибо Роману за такой замечательный пост. Если будет время и желание написать еще, смело присылай, я с радостью опубликую.
Дополнение: Простая и эффективная (параллелизуемая) реализация генетического алгоритма на Haskell