Метрики и мониторинг в Akka при помощи Kamon
Когда вы работаете с Akka, и вообще акторами, очень многое может пойти не так. Очереди сообщений могут переполняться, актор может начать перемножать матрички, заняв собой трэд, или, наконец, где-то могут просто начать сыпаться эксепшены. Пока у вас одна нода и мало пользователей, можно, конечно, просто быть на телефоне 24/7 и разбираться в проблемах по логам, отладочным ручкам, ну или remsh, если вы пишите на Erlang. Как только нод становится больше и проект выходит из альфы, такой подход становится совершенно нерабочим. На помощь приходит Kamon.
Примечание: Кстати, если вдруг вам доводилось слышать про Typesafe Console, знайте, что эта штука умерла. Нечто похожее осталось в Activator UI (который вскользь упоминался в заметке про Play), но оно не особо удобно и применимо только во время разработки, и то с натяжкой. Интересно, что сам Typesafe не особо трубил о смерти Typesafe Console и даже в списке рассылки разместил соответствующую информацию 1 апреля, чтобы окончательно всех запутать.
Kamon – эта такая штука для сбора метрик в проектах, использующих Akka, Play Framework или Spray. Вам лишь нужно сказать «использовать Kamon» и указать ему, куда нужно складывать метрики. Все остальное – дело техники. Kamon умеет писать метрики в StatsD, Datadog и New Relic. При этом Kamon очень гибок. В частности, вы можете сказать «собирай информацию обо всех акторах, кроме» или наоборот, «собирай метрики только для таких-то акторов».
На самом деле, помощью Kamon можно не только репортить метрики, но и пробрасывать трейсы-контексты, а также более правильно определять причину ask timeout. Библиотека постоянно развивается, и в будущих версиях может появится еще какой-нибудь полезный функционал. Однако в рамках этой заметки мы сосредоточимся именно на метриках.
Для определенности скажем, что мы решили использовать Datadog. В принципе, если вы решите использовать, например, StatsD, то настройка будет мало чем отличаться.
Datadog – это очень могучий SaaS для хранения метрик и мониторинга системы. Помимо прочего, Datadog интересен своей способностью интегрироваться дофига с чем, а также вполне разумной ценовой политикой. Если в вашем проекте есть возможность воспользоваться SaaS для метрик и мониторинга, внимательно присмотритесь к Datadog. Получится намного быстрее, дешевле и удобнее, чем поднимать что-то свое.
Запись метрик в Datadog происходит не напрямую, а через Datadog Agent. Это такой демон, выполняющий несколько функций, и разделенный на компоненты, каждый из которых выполняет только одну функцию:
- Forwarder отвечает за отправку всех метрик в Datadog;
- Collector собирает информацию о машине (память, cpu, диск, трафик);
- Dogstatsd предоставляет StatsD API для записи метрик приложениями;
- Supervisord рулит предыдущими тремя компонентами;
По умолчанию включены все компоненты, но при необходимости, например, можно отключить collector.
Информацию по установке агента вы можете найти здесь или, если вы уже зарегистрированы в системе, в разделе Integrations → Agent. В последнем предлагаются более быстрые варианты в стиле curl ... | sh.
В Ubuntu Linux после установки агента рулить им можно как-то так:
sudo service datadog-agent restart
Конфиг агента (api key, какой интерфейс слушать и тд):
/etc/dd-agent/datadog.conf
Логи агента с разбивкой по названным выше компонентам:
/var/log/datadog/
Описание протокола dogstatsd (который представляет собой расширенный протокол StatsD) вы можете найти здесь. Вот так, к примеру, можно записывать счетчики:
echo "test.counter:10|c" | nc -u -w0 127.0.0.1 8125
Хорошо, теперь нам есть, куда писать метрики. Осталось устроить все на стороне приложения. Пример того, как это делается, можно найти в этом архиве. За основу мною был взять пример, который генерирует Typesafe Activator. Как оказалось, в этом примере многое нужно доводить до ума. Рассмотрим основные моменты.
Файл build.sbt:
val kamonVersion = "0.3.4"
libraryDependencies ++= Seq(
"com.typesafe.akka" %% "akka-actor" % "2.3.5",
"io.kamon" %% "kamon-core" % kamonVersion,
"io.kamon" %% "kamon-datadog" % kamonVersion,
"io.kamon" %% "kamon-log-reporter" % kamonVersion,
"io.kamon" %% "kamon-system-metrics" % kamonVersion,
"org.aspectj" % "aspectjweaver" % "1.8.2"
)
aspectjSettings
javaOptions <++= AspectjKeys.weaverOptions in Aspectj
fork in run := true
Здесь самое главное – это прикручивание AspectJ, через который Kamon и делает всю свою магию. Также обратите внимание на используемый здесь пакет kamon-system-metrics. Он позволяет собирать разные полезные метрики о самой JVM, в том числе время, потраченное на сборку мусора.
Файл project/plugins.sbt:
resolvers += Resolver.typesafeRepo("releases")
addSbtPlugin("com.typesafe.sbt" % "sbt-aspectj" % "0.10.0")
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.12.0")
Благодаря плагину sbt-aspectj Kamon будет работать при запуске приложения через sbt run.
Файл src/main/resources/application.conf:
akka {
loglevel = INFO
extensions = ["kamon.metric.Metrics", "kamon.datadog.Datadog",
"kamon.system.SystemMetrics"]
}
kamon {
metrics {
filters = [
{
actor {
includes = [ "user/*", "user/worker-*" ]
excludes = [ "system/*" ]
}
},
{
trace {
includes = [ "*" ]
excludes = []
}
}
]
}
datadog {
hostname = "127.0.0.1"
port = 8125
flush-interval = 1 second
max-packet-size = 1024 bytes
report-system-metrics = true
includes {
actor = [ "*" ]
trace = [ "*" ]
dispatcher = [ "*" ]
}
application-name = "kamon_test"
}
}
Здесь мы прикручиваем компоненты Kamon'а в виде расширений для Akka и настраиваем их – по каким акторам собирать метрики, куда и как часто эти метрики отправлять, и так далее.
Еще интересен файл src/main/scala/sample/kamon/RandomNumberActor.scala:
import kamon.Kamon
import kamon.metric.UserMetrics
// ...
val counter = Kamon(UserMetrics).registerCounter("generate-number")
// ...
counter.increment()
Как видите, здесь приводится пример использования пользовательских метрик.
Если все было сделано правильно, то при запуске приложения в Datadog посыпятся метрики, при помощи которых вы без труда сможете строить графики вроде следующих.
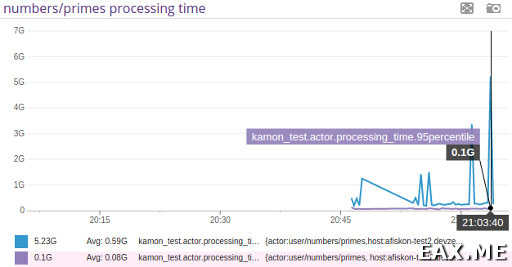
Здесь мы следим за временем обработки сообщений заданным актором (максимум и 95-й процентиль). Заметьте, что все метрики называются одинаково для всех акторов. Но при этом мы можем фильтровать метрики по имени актора или хосту, на котором крутится нода, поскольку метрики идут вместе с тэгами (см {actor:... внизу графика). Кроме того, мы можем группировать метрики по множеству акторов, поскольку Kamon также снабжает метрики тэгами с префиксами, полученными из полного имени (пути) актора.
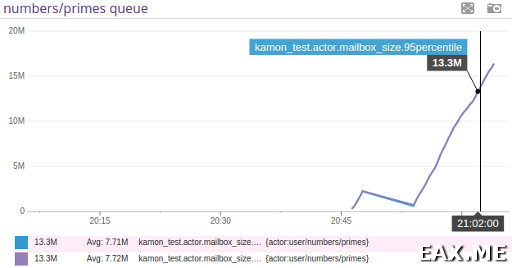
А этот график недвусмысленно намекает нам, что у актора копятся сообщения в очереди. Если вы недавно приступили к настройке Datadog, незамедлительно настройте алерты на эту ситуацию!
При использовании Kamon есть один важный нюанс. Допустим, вы собираете standalone jar. Тогда помимо этого jar вам придется включить в deb-пакет или чем вы там катите еще и aspectjweaver, а приложение запускать как-то так:
java -javaagent:aspectjweaver-1.8.2.jar -jar kamon-test.jar
Но упаковка в deb-пакеты – это уже тема для отдельной заметки.
Вот, в общем-то, и все, о чем я хотел сегодня рассказать. Следует только добавить, что у Kamon есть официальный список рассылки.
Дополнение: Если вы вдруг используете Play, примите во внимание, что он инициализирует ActorSystem лениво, поэтому Kamon не будет слать никаких метрик до тех пор, пока кто-нибудь не пошлет первый HTTP-запрос. Для решения этой проблемы можно принудительно вычислить ActorSystem в onStart.
Дополнение: На момент написания этих строк Kamon репортил в качестве GC time суммарное время в миллисекундах, потраченное на сборку мусора с момента запуска приложения. Это поведение может измениться в будущем. А пока не пугайтесь, если увидите на графиках GC time в районе пятнадцати минут. Вообще, как оказалось, мониторинг GC time существенно усложняется, например, тем, что сборка мусора может происходить параллельно с работой кода самого приложения. Тем не менее, если вы полны решимости написать пользовательские метрики для наблюдения за GC, кое-какие примеры кода можно найти здесь и тут.
Дополнение: Вас также могут заинтересовать статьи Трассировка в Akka при помощи библиотеки Kamon и Устанавливаем связку из Prometheus и Grafana.